Bonjour Knoxville,
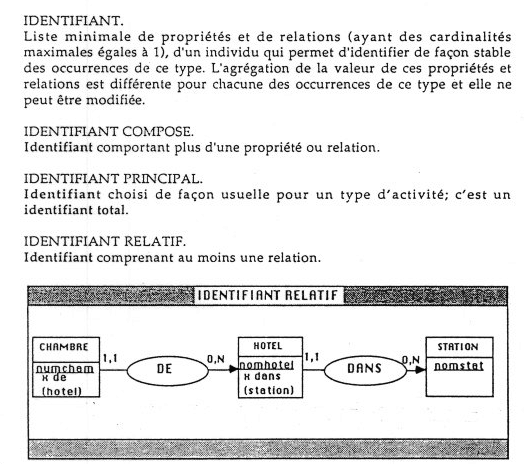
Au niveau conceptuel, à chaque entité-type on affecte un identifiant, dont lobjet est de distinguer des jumeaux parfaits. Pour leur part, les associations-types nont pas didentifiant en propre, mais héritent de lunion des identifiants des entités-types quelles mettent en relation.
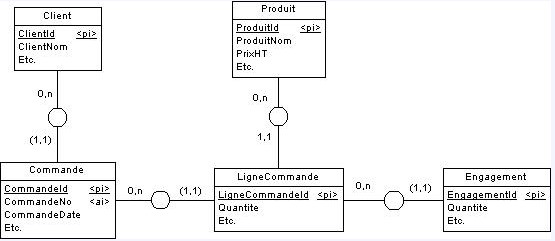
Supposons que vous soyez dans une entreprise recevant des commandes de la part de ses clients. Considérons maintenant lentité-type Commande. Elle a notamment pour propriétés : Lidentifiant (disons CommandeId), affecté a priori par le concepteur (acte réflexe).
Le numéro de commande connu des utilisateurs (et qui peut être utilisé comme identifiant sil est fourni par le système, sil est invariant et sil garantit la règle dunicité).
La référence du client.
La date de la commande.
Lensemble des lignes de commande.
Etc.
En Merise, la règle est que les attributs dune entité-type ne puissent prendre quune seule valeur. Or, les lignes de commande correspondent à un attribut multivalué, en infraction avec la règle. En conséquence, ces lignes de commande vont faire lobjet dune entité-type LigneCommande. Pour autant, cette entité-type pèse bien moins lourd que celle qui lui a donné naissance, elle est qualifiée de "faible" (weak entity). On peut encore considérer les lignes de commande comme constituant un composant de la commande. Au nom dun principe érigé en règle, LigneCommande est techniquement une entité-type mais ontologiquement et sémantiquement, viscéralement devrais-je dire, elle nest toujours quune propriété de Commande : par exemple, la suppression dune commande entraîne automatiquement la suppression de toutes ses lignes de commande, qui nont aucune raison de rester en vie et de sopposer à la destruction de l'objet qu'elles composent.
Quoi quil en soit, lentité-type LigneCommande doit être affectée dun identifiant, appelons-le LigneCdeId. Il y a deux écoles :
La première dentre elles préconise que cet identifiant soit représenté par un attribut unique, comme ce fut systématiquement le cas jusque dans les années quatre-vingts.
La deuxième, moins simpliste, reconnaît que LigneCommande à linstar des associations hérite de lidentifiant de Commande. Mais, pour distinguer chaque ligne de commande au sein dune commande, on complète lidentifiant de LigneCommande par un attribut supplémentaire, en loccurrence LigneCdeId qui perd son caractère absolu et devient relatif à CommandeId.
Pour résumer, selon la deuxième école : Lentité-type Commande a pour identifiant {CommandeId}
Lentité-type LigneCommande a pour identifiant {CommandeId, LigneCdeId} :
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
Commande (CommandeId, CommandeDate, ClientId, ...)
1 d1 c1
2 d2 c2
... ... ...
LigneCommande (CommandeId, LigneCdeId, ProduitId, Quantité, ...)
1 1 p1 q1
1 2 p2 q2
1 3 p3 q3
2 1 p4 q4
2 2 p5 q5
2 3 p6 q6
... ... ... ... |
Personnellement, je suis un adepte de lidentification relative : Pour les raisons sémantiques que jai mentionnées.
Ensuite, parce que cela a une incidence déterminante à lautre bout de la chaîne, cest-à-dire au stade de la Production informatique.
Jai quand même plus de quarante ans dexpérience concernant les très grands volumes de données, je me suis engagé auprès de nombreuses grandes entreprises quant à la performance de leurs applications et jai pu apprécier lefficacité décisive de lidentification relative à ce sujet.
En effet, au niveau physique, pour faire simple et pour reprendre lexemple des lignes de commande, en fonction de lattribut CommandeId, celles-ci pourront être regroupées dans une même page (clustering) et faire lobjet dune seule entrée/sortie. Sinon, au pire, chaque ligne sera dispersée dans une page distincte, ce qui fait quau lieu dobtenir les lignes en une seule entrée/sortie, il faudra donc compter autant dentrées/sorties que de lignes. Ainsi malgré toute la puissance CPU dont vous disposerez, vous serez bloqué par les attentes de fin dentrée/sortie, phénomène connu sous le nom dI/O bound (ou I/O wait), qui énerve singulièrement celui qui le subit. Sur des volumes faibles ou pour des transactions légères, cela est quasiment transparent, mais peut devenir dramatique quand vous manipulez simultanément dix tables de dix à cent millions de lignes et au delà. Plus dune fois jai effectué des missions en catastrophe, diagnostiqué que lI/O bound était le coupable et fait en sorte que les temps de traitement des batch de nuit tiennent dans la fenêtre imposée et ne retardent plus le démarrage du télétraitement diurne.
On pourra vous rétorquer que le regroupement (clustering) des lignes de commande sur CommandeId ne nécessite pas le mécanisme de lidentification relative. Mais, changement de chanson si vous voulez propager cet attribut au-delà des lignes de commande et continuer à éviter lI/O bound. Considérez que lentité-type LigneCommande comporte un attribut multivalué donnant lieu à une entité-type Engagement (on sengage à livrer en fonction de ce que lon a en stock, en cours darrivage, en fabrication, etc.) : le regroupement des engagements sur CommandeId simpose là encore. Même chose si chaque engagement fait à son tour lobjet de plus dune livraison (par exemple, on ne peut pas tout mettre sur le même camion).
Je joins un schéma que jai déjà proposé à Snoopo et consorts. Vous noterez que même lentité-type Commande est identifiée relativement à Client. Exercice : à vous de justifier ce choix.
En revanche, lentité-type Client est considérée comme "indépendante". Paradoxalement, le regroupement des clients pourrait poser des problèmes de contention dans un contexte transactionnel, mais je suppose que vous avez étudié le problème de la concurrence daccès des transactions en mise-à-jour et comprendrez cela (supposez quau même moment plusieurs utilisateurs créent des clients). Le phénomène de contention joue moins avec les commandes et lignes de commande, car une commande donnée est traitée (en principe) par un utilisateur unique.
Sur ce schéma (Power AMC), vous noterez que, par exemple, lattribut CommandeId ne figure pas comme attribut de lentité-type LigneCommande, mais au niveau tabulaire il sera bien présent. Vous noterez aussi que LigneCommande nest pas identifiée relativement à Produit : une ligne de commande nest pas un composant dun produit.
Il est encore possible que la recherche des données Produit engendrent de lI/O bound, cest pourquoi ces données devront être accédées au plus une fois, le plus tard possible, lors du traitement chargé de fournir ces données. Mais là, on en arrive au prototypage des traitements et il sagit dune autre histoire...
Pour conclure, au niveau conceptuel, lidentification relative se justifie pour des raisons ontologiques et sémantiques. Ses conséquences au niveau physique sont déterminantes pour la réduction des temps des traitements lourds manipulant de grands volumes de données.
A vous de jouer.










 Répondre avec citation
Répondre avec citation









.jpg)







RVA.jpg)
MOO_by_Ego.png)
Commande_IEF.png)
Commande_Merise.jpg)
Commande(Merise)OldTime.jpg)

Partager