
fsmrel
[Actualité] Le modèle relationnel de données et la mise à jour des vues : une saga
par , 20/05/2015 à 00h57 (2855 Affichages)
____________________________________________________
Depuis lapparition du modèle relationnel de données de Ted Codd en 1969, la perception que lon a de la mise à jour des vues, a évolué de façon harmonieuse si lon peut dire.
Le terme lui-même de vue au sens relationnel du terme (qui na pas grand-chose à voir avec feue la vue externe (external view) de lANSI/PARC) a été défini en 1974 dans un article commis par trois chercheurs de chez IBM, à savoir Chamberlin, Gray et Traiger : Views, Authorization and Locking in a Relational Data Base System (révision datée ici de 1975), les propos étaient les suivants au sujet de la mise à jour des vues :
(1) Règle du rectangle : seule peut être affectée linformation visible dans le cadre de la vue ;
(2) Règle dunicité : si la vue comporte N lignes, après mise à jour, elle doit là aussi comporter N lignes.
En notant que dans cet article (ou SQL était appelé SEQUEL), il est traité nommément des mises à jour des vues de jointure.
En 1976, SEQUEL est devenu SEQUEL 2 (avant dêtre renommé : « SEQUEL was later renamed to SQL by dropping the vowels, because SEQUEL was a trade mark registered by the Hawker Siddeley aircraft company », cf. The 1995 SQL Reunion: People, Projects, and Politics).
Voici ce quon lit dans larticle commis par Chamberlin et sa nouvelle équipe (qui sest étoffée) : SEQUEL 2: A Unified Approach to Data Definition, Manipulation, and Control , où manifestement les vues de jointure ne sont plus mise à jour « mettables » :
Chamberlin_et_al(vues).png)
Sautons en 1982. Je compulse louvrage suivant de Jeffrey D. Ullman : Principles of Database Systems, 2nd edition (1982) ISBN : 0-7167-8069-0. Cest une excellente référence, que lon doit avoir à portée de main (vous pouvez lacquérir voir ici pour une dizaine deuros, port compris)...
A cette époque, Jeff était perplexe quant à la mise à jour des vues :
A serious problem with this sort of facility is that updates to a view often have side effects on parts of the database that are not in the view [...] it is also unclear, in relational systems, what the deletion of some components of tuple means if there are other attributes of the relation that are outside the view and that therefore should not be deletable by a user seeing only the view. For these reasons, many updates to views must be ruled out by the system.
Certes, lexposé de Jeff est pour le moins informel, mais il représente lopinion de la communauté académique au début des années quatre-vingts.
Toutefois, des chercheurs comme Claude Delobel (inventeur de la photographie de la base de données (instantané, snapshot) et Michel Adiba fournissent des exemples précis de mise à jour des vues, mais dans le cadre de SEQUEL, langage avec lequel une table ne correspond pas forcément à une relation (possibilité de lignes et/ou de colonnes en double, etc.) Ils concluent que si lon veut réaliser des mises à jour au travers de vues en SEQUEL, alors il faut y interdire les jointures (gloups !), les GROUP BY, les UNIQUE (DISTINCT en SQL) et les fonctions de calcul. Je vous renvoie au chapitre 6 (page 182) de leur remarquable ouvrage Bases de données et systèmes relationnels (1982).
En 1984, dans la version 4 de An introduction to Database Systems (volume I), Chris Date nous montre un chouette diagramme, montrant quelle est la situation quant à la mise à jour des vues :
Date rappelle que les vues de jointure (naturelle) peuvent être mises à jour, mais que les SGBD SQL ne le permettent pas (je rappelle que cétait il y a une trentaine dannées). Ainsi, avec SYSTEM R (le prototype dIBM, lancêtre de tous les SGBD SQL), une table ne peut être mise à jour que si elle fait référence à une seule table (c'est-à-dire dans le FROM), chaque ligne de la vue correspond à une seul ligne identifiable de cette table, et chaque colonne de la vue correspond à une seule colonne identifiable de len-tête de la table : la table doit pouvoir mériter le label de relation . Néanmoins, pas de jointure dans la vue, pas dunion, pas de GROUP BY, pas de champs calculés. Air connu...
En 1986, à loccasion de ses « 12 rules » qui firent grand bruit dans le Landerneau des systèmes de gestion des bases de données (An Evaluation Scheme for Database Management Systems that are claimed to be Relational), Ted Codd énonça la règle 6 (View Updating Rule) :
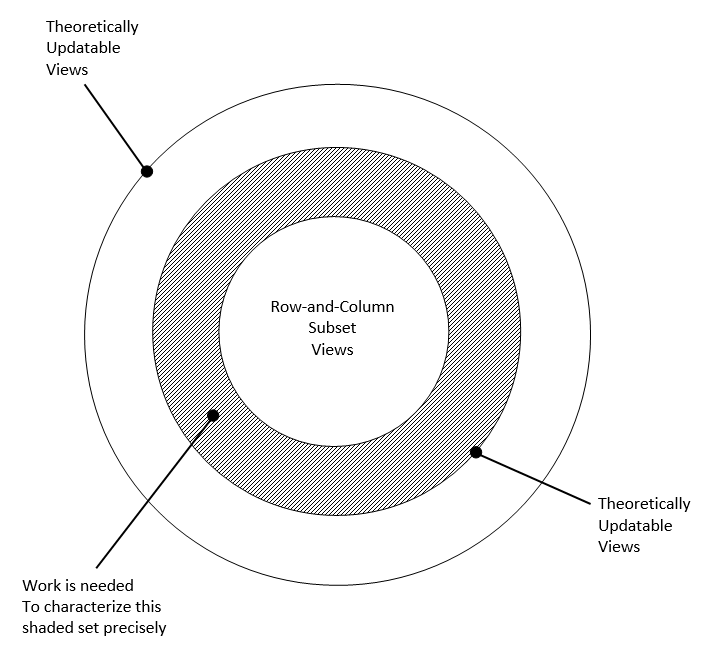
Rule 6: All views that are theoretically updatable are also updatable by the system.
Note that a view is theoretically updatable if there exists a time-independent algorithm for unambiguously determining a single series of changes to the base relations which will have as their effect precisely the requested changes in the view. In this regard, update is intended to include insertion and deletion, as well as modification.
Bien entendu, Chris Date na pas manqué de réagir, voyez dans Relational Database Writings 1989-1991 : « An Assessement of Codds Evaluation Scheme » (ISBN 0-201-54303-6, encore une poignée deuros à bien placer...) :
But is there an implication that we know exactly what it is that characterizes the class of theoretically updatable views? Is the time-independent algorithm always known? I am not aware of any documented definition of that class or of such an algorithm. And if those definitions in fact do not exist, (or at least are not yet known), then this rule is rather hard to apply, to say the least.
En 1990, quand il publia sa somme The Relational Model for Database Management, Version 2, Codd tint compte de larticle commis en 1988 par H. W. Buff : Why Codd's Rule No. 6 Must be Reformulated. Il fournit une version révisée, très détaillée du sujet (une quarantaine de pages cette fois-ci), où les clés primaires jouent un rôle non négligeable, of course. Je vous renvoie aux chapitres 16 « Views » et 17 « View Updatability » de louvrage, mais je vous conseille de vous munir daspirine avant dentamer la lecture...
Au sujet de cette règle 6, vous pouvez aussi vous reporter à larticle figurant dans Wikipedia.
Et puis le temps a passé. Dans les versions successives de An Introduction to Database Systems, Chris Date fut de plus en plus précis sur les conditions à remplir pour quune vue puisse être mise à jour, opérateur par opérateur (projection, restriction, jointure, union, différence, etc.) et par type dinstruction : INSERT, UPDATE, DELETE. Il commença à mette le grand braquet à partir de la V6 de louvrage.
Je pense que dans le cadre de la théorie relationnelle, le débat est clos, je vous renvoie à louvrage de Chris Date : View Updating and Relational Theory - Solving the View Update Problem. En revanche, concernant le Sorry Query Language, c'est une autre paire de manches, il y a encore du pain sur la planche...
SQL et la mise à jour des vues de jointure (un serpent de mer...) :
En ce qui concerne JOIN (sous-entendu INNER), la norme SQL autorise la mise à jour et Oracle sy est mis (Updating a Join View).
Suite à la parution de larticle de Buff (controversé du reste par lexcellent David McGoveran dans Accessing and updating Views and Relations in a Relational Database), au moins tout le monde sest mis daccord sur le fait que pour mettre à jour les vues, on ne pouvait se dispenser de la présence des clés primaires.
Pour plus de précisions, sur ce que dit la norme SQL, se reporter à la référence :
SQL and Relational Theory, 2nd Edition, How to Write Accurate SQL Code, où sont recensées quelques bévues commises par ceux qui font la norme.
Comme dit David McGoveran (copain de Date), « The SQL Standard has been and continues to be a barrier to developing (let slow implementing) approaches for general view updating ». Fermez le ban.
____________________________________________________________










