par , 01/08/2016 à 09h00 (8470 Affichages)
JavaScript bien qu'omniprésent de nos jours reste un langage très décrié à cause notamment de nombreuses approximations dans les spécifications de sa syntaxe. Mais il serait simpliste et erroné de croire que le succès de ce langage n'est dû qu'à un phénomène de mode (cela fait une vingtaine d'années que cela dure), ou que ses partisans sont de mauvais développeurs répandant de mauvaises pratiques de programmation.
Car au-delà des concepts phares comme l'héritage par prototype qui est à mon goût survendu, la véritable force du langage ne réside pas vraiment en lui, mais autour. Cette force, c'est son fonctionnement asynchrone dont les fondements ne sont pas toujours bien compris.
JavaScript : monothread et asynchrone
JavaScript est un langage qui a été pensé pour évoluer dans un environnement monothread et asynchrone.
Le terme thread pourrait être traduit en première approximation par processus. Le fait que le moteur JavaScript (grosso modo l'interpréteur JavaScript) soit monothread signifie que le moteur ne peut interpréter qu'une seule et unique instruction à la fois, via sa seule et unique pile d'exécution (Call Stack). Le principal avantage de ceci étant la simplicité.
Le terme asynchrone fait référence au comportement de certains traitements dans JavaScript qui peuvent être délégués en dehors du moteur. Dans le cas d'une page Web, les traitements asynchrones seront délégués au navigateur. À noter que bien que le moteur JavaScript soit monothread, l'hôte (eg. le navigateur ou NodeJS) peut lui être multithreads. Les threads pouvant être l'application JavaScript en cours, le rendu de l'interface utilisateur (UI), la gestion des entrées/sorties (IO), etc.
Sans cette possibilité de réaliser des appels asynchrones, une application JavaScript serait condamnée à bloquer le navigateur le temps de son exécution.
 Notification de blocage de Firefox par un script
Notification de blocage de Firefox par un script
Circuit de l'asynchrone
L'asynchrone en JavaScript repose sur un circuit partant de la pile d'exécution, sortant du moteur JavaScript via les API du système hôte (Host APIs) qui peut être le navigateur ou NodeJS, la file d'attente des callbacks (Callback Queue), la boucle des événements (Event Loop), pour enfin revenir au moteur JavaScript sur la pile d'exécution.
Il est important de noter que le seul composant du moteur JavaScript directement impliqué dans le circuit de l'asynchrone est la pile d'exécution. Les autres composants que sont les API du système hôte, la file d'attente des callbacks et la boucle des événements ne font pas à proprement parler partie de ce moteur JavaScript.
Il est ainsi possible de dire que JavaScript est un peu plus qu'un langage, c'est aussi une architecture.
 Composants du circuit de l'asynchrone
Composants du circuit de l'asynchrone
Pile d'exécution
Un programme comporte généralement des fonctions appelant d'autres fonctions (ou s'appelant elles-mêmes). Le rôle de la pile d'exécution est d'assurer le suivi de la chaîne d'appel en mémorisant la fonction et son contexte d'exécution (variables locales et paramètres d'appel). Un appel d'une fonction A() dans le contexte global empilera un premier niveau sur la pile d'exécution. Si cette fonction A() appelle en son sein une fonction B(), alors un second niveau sera empilé sur la pile. Et si cette fonction B() appelle une fonction C(), alors un troisième niveau sera empilé sur la pile. Un niveau de la pile n'est retiré que lorsque la fonction appelée a terminé son exécution. C'est pourquoi lors d'appels récursifs mal implémentés, il est possible de dépasser la capacité de la pile et obtenir le fameux message d'erreur « stack overflow ».
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| function A() {
// Etat 1
B();
// Etat 5
}
function B() {
// Etat 2
C();
// Etat 4
}
function C() {
// Etat 3
}
// Etat 0
A();
// Etat 6 |
Appels imbriqués de fonctions
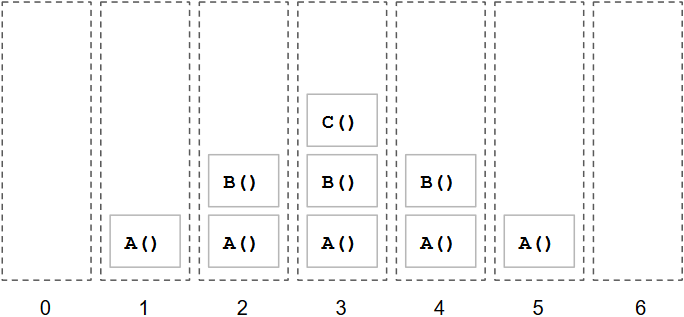 États successifs de la pile d'exécution lors d'appels imbriqués
États successifs de la pile d'exécution lors d'appels imbriqués
APIs du système hôte
Le système hôte (eg. navigateur, NodeJS) fournit toute une panoplie de fonctions et d'objets (API) au moteur JavaScript pour interagir avec lui ou avec le système d'exploitation. Certaines de ces fonctions sont asynchrones comme XMLHttpRequest.send(), FileReader.readFile() dans le domaine des accès aux ressources ou encore le listener du DOM pour ce qui est de la gestion des événements, asynchrones par essence.
Le programme principal JavaScript doit avoir la possibilité de savoir si un traitement asynchrone qu'il a appelé est terminé puis d'exploiter le résultat de ce traitement asynchrone en conséquence. C'est là qu'interviennent les fonctions callbacks. Il est courant en JavaScript que les callbacks soient des fonctions anonymes passées en paramètre et définies au moment même de l'appel de la fonction asynchrone.
1
2
3
4
5
6
7
8
9
10
11
| var req = new XMLHttpRequest();
req.open('GET', 'http://www.mozilla.org/', true);
req.onreadystatechange = function callback(aEvt) { // fonction callback
if (req.readyState == 4) {
if(req.status == 200)
dump(req.responseText);
else
dump("Erreur pendant le chargement de la page.\n");
}
};
req.send(null); // traitement asynchrone |
Requête HTTP asynchrone au format XML sous un navigateur
1
2
3
4
5
6
| var fs = require('fs');
// traitement asynchrone
fs.readFile('DATA', 'utf8', function callback(err, contents) { // fonction callback
console.log(contents);
}); |
Lecture asynchrone d'un fichier sous NodeJS
File d'attente des événements
Une fois que le traitement asynchrone est terminé ou qu'un événement particulier survient, la callback qui a été fournie en paramètre est insérée dans la file d'attente des callbacks avant d'être prise en compte par la boucle des événements.
Boucle des événements
La boucle des événements a pour but de surveiller l'état de la pile d'exécution. Si cette dernière est vide d'instruction à exécuter, la boucle des événements déplacera la callback en attente dans la file vers la pile d'exécution, permettant à cette callback d'être ainsi exécutée.
Déroulement
Pour mieux illustrer l'implication des différents composants dans un appel asynchrone, nous allons nous définir une fonction getData() qui appellera la fonction asynchrone standard setTimeout().
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| var k = 0;
// Définition de la fonction getData()
function getData(callback) {
console.log('getData()');
setTimeout(function setTimeoutCB(counter) { // callback asynchrone
console.log('setTimeoutCB()');
callback(null, counter);
}, 500, ++k);
}
// Appel de la fonction getData()
getData(function getDataCB(error, data) { // callback synchrone
console.log('getDataCB()');
console.log('data: ', data);
}); |
On peut constater dans le code ci-dessus, que la fonction setTimeout() appelée à l'intérieur de la fonction getData() appelle une fonction callback que nous avons nommée setTimeoutCB() pour la clarté du propos, mais qui aurait très bien pu être anonyme.
Cette fonction setTimeoutCB() a ici pour tâche d'appeler la fonction callback() qui est un paramètre de la fonction getData(). C'est une des caractéristiques des fonctions callbacks.
Lors de l'appel de la fonction getData(), une fonction callback getDataCB() lui est fournie en paramètre.
Regardons ce qu'il se passe lors de cet appel.
(1) Après que les fonctions getData() puis setTimeout() ont été empilées sur la pile d'exécution, la fonction setTimeout() qui fait partie de l'API du navigateur, est appelée et est prise en charge par celui-ci de façon asynchrone. À noter que cet appel à la fonction setTimeout() est la dernière instruction directement exécutée par le programme principal qui arrive ici à son terme. À ce moment, la pile d'exécution est vide.
(2) Le décompte du délai s'effectue dans un thread à part, et lorsque le délai est épuisé, la fonction callback qui a été passée en paramètre de setTimeout(), setTimeoutCB(), est envoyée vers la file d'attente. Notons que les paramètres de setTimeoutCB() sont fournis par setTimeout(). Ici, il s'agit juste d'un compteur numérique valant 1, mais avec d'autres fonctions asynchrones, ce pourrait être un message d'erreur ou des données binaires. L'important est d'avoir à l'esprit que les paramètres de la fonction callback sont fournis par la fonction asynchrone appelante.
(3) La boucle des événements détecte la présence d'une callback, setTimeoutCB(), dans la file d'attente, et s'assure que la pile d'exécution est bien vide. Si c'est le cas, la boucle des événements envoie la callback sur la pile d'exécution où elle est exécutée.
Suite à cela, ce qui n'est pas schématisé, c'est l'empilement par dessus setTimeoutCB(), de la fonction callback() qui est le paramètre de getData() faisant référence à getDataCB(). Le fait que setTimeoutCB() ait toujours accès au paramètre callback vient de la propriété des fermetures en JavaScript (cf. article). La fonction setTimeoutCB() n'étant pas elle une fonction asynchrone, contrairement à setTimeout(), il n'y a pas d'appel à l'API du navigateur, pas de passage par la file d'attente et pas d'intervention de la boucle des événements pour exécuter la fonction. Il s'agit là de traitements synchrones qui restent donc sous l'entière responsabilité du moteur JavaScript.
Remarque : N'hésitez pas à relire plusieurs fois le code, le schéma et les explications pour bien visualiser le déroulement.
Conclusion
Les mécanismes de l'asynchrone en JavaScript ne sont pas très compliqués à comprendre, mais non triviaux à expliquer comme on vient de le voir. Il n'existe finalement pas énormément de ressources à ce sujet sur le Web. J'espère tout de même que ce bref exposé vous aura aidé à mieux comprendre ce qui se déroule « sous le capot » lorsque vous utiliserez des fonctions asynchrones et des callbacks.
Il existe un outil en ligne sur le Web qui permet de visualiser dynamiquement le déroulement d'un code asynchrone. Son auteur, Philip Roberts, explique en anglais plus en détail le fonctionnement de l'asynchrone dans cette vidéo ci-dessous et dont cet article s'est largement inspiré.
N'hésitez pas à partager ce billet si vous l'avez trouvé utile.
Bon développement !












