





















En 1964 a été construit le premier superordinateur, nommé Control Data 6600, avec une puissance de calcul dun mégaflops, cest-à-dire un million dopérations en virgule flottante chaque seconde (comme additionner deux nombres à virgule). Il a été conçu par Seymour Cray, qui a lancé la société Cray, connue pour son activité dans les supercalculateurs.
Vingt et un ans plus tard, en 1985, la barre du gigaflops a été franchie par Cray-2. Actuellement, un processeur haut de gamme (comme un Intel i7 de dernière génération) fournit approximativement cent gigaflops.
Une dizaine dannées plus tard, en 1997, ASCI Red explose le téraflops, mille milliards dopérations en virgule flottante par seconde ; dans cette série de records, cest le premier à ne pas être associé au nom de Cray. Un processeur graphique moderne haut de gamme (comme la GeForce GTX Titan X) dépasse maintenant quelques téraflops.
Il y a presque dix ans, Roadrunner atteignant le pétaflops, en combinant une série de processeurs similaires à ceux utilisés dans les PlayStation 3. Aujourdhui, le plus puissant est Tianhe-2, installé en Chine (alors que les précédents sont américains), avec une cinquantaine de pétaflops. La route semble encore longue jusquà lexaflops, cest-à-dire un milliard de milliards dopérations en virgule flottante par seconde. À nouveau, les États-Unis ont lancé un projet pour atteindre cette puissance de calcul à lhorizon 2020 plus particulièrement, le Département de lÉnergie, le même à investir massivement dans un compilateur Fortran moderne libre.
Ces nombres paraissent énormissimes : un milliard de milliards dopérations par seconde. Outre les aspects purement informatiques, ce genre de projets a une grande importance pour la recherche scientifique : les laboratoires américains de lÉnergie étudient notamment larme nucléaire et la destruction en toute sécurité dogives ; en Europe, le Human Brain Project vise à simuler toute lactivité cérébrale dun cerveau humain au niveau neuronal, ce qui nécessiterait une puissance de calcul de cet ordre de grandeur.
Comment y arriver ?
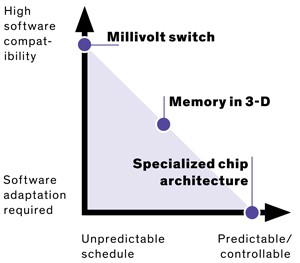
Le département de lÉnergie estime que, actuellement, toutes les technologies nécessaires pour construire un tel superordinateur sont réunies. Cependant, il serait extrêmement difficile de lalimenter : il faudrait un réacteur nucléaire complet pour y arriver ! Même si la construction de réacteurs fait partie de ses compétences, lobjectif de ladministration est de proposer une machine qui ne consomme « que » vingt mégawatts (un réacteur nucléaire produit généralement mille mégawatts). Erik DeBenedictis voit trois technologies pour réduire la consommation du facteur cinquante demandé : des transistors qui opèrent à une tension dun millivolt, la mémoire 3D et les processeurs spécialisés.
En théorie, un transistor peut fonctionner avec des tensions bien plus faibles quactuellement, en passant dun volt à quelques millivolts à peine, ce qui augmenterait lefficacité énergétique des processeurs dun facteur dix à cent à court terme (jusquà dix mille à plus long terme !). La diminution de tension a jusquà présent suivi la loi de Moore, suivant la taille des transistors ; cependant, elle est bloquée depuis une décennie au niveau du volt mais personne ne sait comment y arriver. Plusieurs technologies pourraient néanmoins passer cette barre :
- les transistors FET à tunnel ;
- les technologies MEMS, avec des interrupteurs électromécaniques nanométriques ;
- la nanophotonique, qui exploiterait de la lumière pour transmettre linformation ;
- la nanomagnétique, avec des champs magnétiques qui pourraient créer des circuits non volatils.
Les mémoires empilées (aussi dites « en trois dimensions ») sont dores et déjà en cours de déploiement, sous des noms comme HBM ou HMC, dans les processeurs graphiques haut de gamme ou des accélérateurs spécifiquement prévus pour le calcul scientifique. Ils permettent une grande réduction de la consommation énergétique, dautant plus enviable que lobjectif de vingt mégawatts réserve un tiers de la consommation à la mémoire. Une autre piste serait dabandonner autant que possible la mémoire non volatile, pour passer par exemple à la mémoire résistive, comme la technologie Octane dIntel.
Le troisième axe de recherche propose dexploiter des architectures beaucoup plus spécifiques aux problèmes à résoudre. Elle est déjà exploitée, puisquune bonne partie des superordinateurs les plus puissants utilisent des processeurs graphiques. Cependant, Erik DeBenedictis propose de pousser lidée plus loin encore : installer des processeurs extrêmement spécifiques aux tâches à réaliser, qui seraient activés seulement quand ils sont nécessaires. Pour effectuer dautres types de calculs sur lordinateur, il faudrait alors installer dautres processeurs spécialisés, ce qui nest plus déraisonnable actuellement, au vu du prix des puces spécialisées.
Des compromis à réaliser
Ces trois pistes ont lair intéressantes, mais nont pas du tout les mêmes propriétés quant au modèle de programmation actuel : si la physique derrière les processeurs change complètement, ils restent programmables de la même manière ; par contre, pour exploiter efficacement de nouveaux processeurs spécialisés, il faudrait changer complètement sa manière de pensée. La mémoire est dans une situation intermédiaire : empilée sur le processeur, les délais daccès changent radicalement, lancien code nest donc plus aussi efficace sil tirait parti de ces spécificités, mais continuera à fonctionner ; au contraire, pour la mémoire résistive, il ny aurait plus de distinction entre la mémoire utilisée pour effectuer les calculs et celle pour le stockage à long terme.
Sources : Three paths to exascale supercomputing (paru en ligne sous le titre Power problems threaten to strangle exascale computing), FLOPS.
Ce contenu a été publié dans HPC et calcul scientifique, Matériel par dourouc05.
Et vous ?
Quelle utilité voyez-vous au développement de ces superordinateurs ?
 Répondre avec citation
Répondre avec citation








Partager