Bonsoir PanK7,

Envoyé par
PanK7
jai quelques petites questions concernant surtout mes deux associations ternaires. Celle entre Incident SuivIncident et Machine pour moi est obligatoire (je peux me tromper hein), car je dois garder un historique de tous les incidents qui se sont produits. Jai juste un problème au niveau des cardinalités est-ce bien ça ?
Selon les cardinalités portées par les pattes de lassociation SeProduire, un incident participe une et une seule fois à lassociation, un suivi dincident y participe aussi une et une seule fois, tandis quune machine peut y participer de 0 à N fois. Ça cest la lecture merisienne, laquelle nest pas forcément la lecture uémélienne...
Quoi quil en soit, selon la lecture merisienne (le verbe concerner est sémantiquement plutôt pauvre, mais on fera avec) :
Un incident concerne une et une seule machine ;
Un incident concerne un et un seul suivi ;
Un incident concerne un et un seul moment (c'est-à-dire date et heure de lincident) ;
Un suivi concerne une et une seule machine ;
Un suivi concerne un et un seul incident ;
Un suivi concerne un et un seul moment ;
Une machine est concernée par 0 à N incidents ;
Une machine est concernée par 0 à N suivis ;
Une machine est concernée par 0 à N moments ;
Un moment concerne de 0 à N machines ;
Un moment concerne de 0 à N incidents ;
Un moment concerne de 0 à N suivis.
Ces règles de gestion des données sont elles celles que vous auriez fournies ?
Supposons que ce soit le cas. Si lon traduit cela dans le cadre de la théorie relationnelle, on a la relvar (variable relationnelle) :
SeProduire {IdIncident, IdSuiviIncident, IdMachine, DateHeureIncident} ;
Et deux clés candidates, conséquences des cardinalités 1,1 merisiennes :
K1 = {IdIncident}, K2 = {IdSuiviIncident}.
La relvar respecte la cinquième forme normale, elle est donc valide et par conséquent votre association lest aussi.
Maintenant, le problème est que les AGL et outils de modélisation merisiens ne produisent pas forcément tous la même chose lors de la dérivation du MCD en MLD (donc ensuite en SQL)...
Exemple avec DB-MAIN
A partir du MCD suivant :
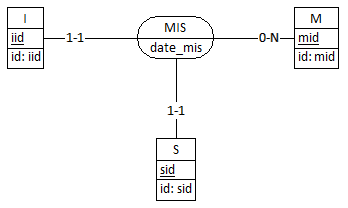
On obtient le MLD valide : 
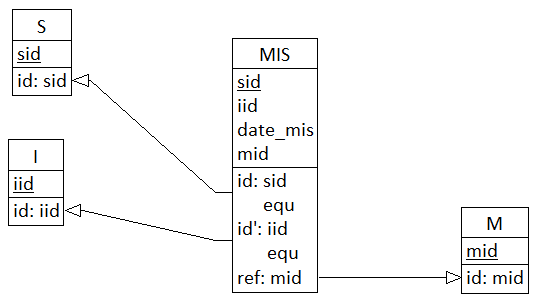
En effet {sid} et {iid} sont identifiants candidats de MIS (donc clés candidates).
Exemple avec JMerise
A partir du MCD (identique) suivant :
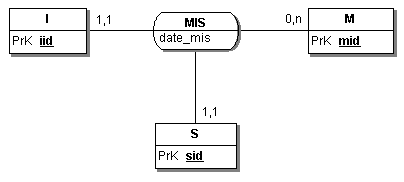
On obtient le MLD non valide : 
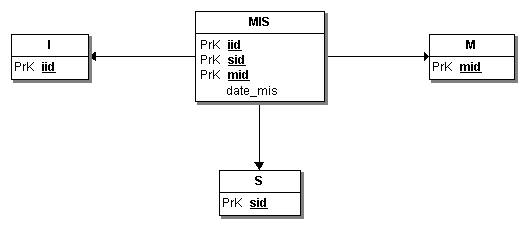
En effet, la table MIS est seulement dotée dune surclé {iid, sid, mid} et daucune clé candidate.
Avant de poursuivre, quelle est votre position quant aux règles de gestion des données que jai conjecturées ? Merci de fournir les règles exhaustives concernant lautre ternaire.
N.B. Les cardinalités portées par les pattes de lassociation AVOIR connectant les entités-types (et non pas les tables, car on est au niveau conceptuel) INCIDENT et NIVEAU_INCIDENT sont à permuter.










")

 Répondre avec citation
Répondre avec citation









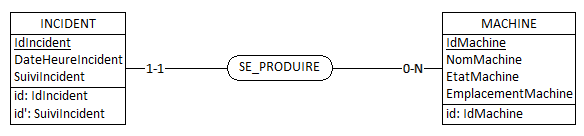

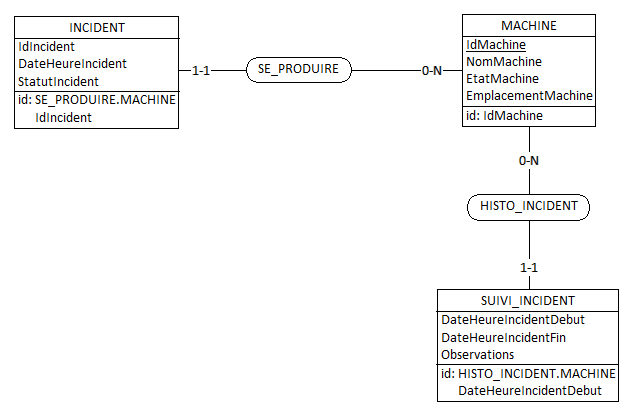

 ! Étant donné que l'entité TYPE_INCIDENT est déjà relié à mon entité INCIDENT je pourrai toujours savoir le type d'incidents qui est survenu non ? Ou alors je dois relier l'entité SUIVI_INCIDENT à mon TYPE_INCIDENT pour garder un historique des types d'incidents qui se sont produits ? Je suis perdu mais je pense que c'est la deuxième solution
! Étant donné que l'entité TYPE_INCIDENT est déjà relié à mon entité INCIDENT je pourrai toujours savoir le type d'incidents qui est survenu non ? Ou alors je dois relier l'entité SUIVI_INCIDENT à mon TYPE_INCIDENT pour garder un historique des types d'incidents qui se sont produits ? Je suis perdu mais je pense que c'est la deuxième solution 
Partager