











Lapplication AI4COVID-19 se base sur lIA pour établir un diagnostic préliminaire en analysant la toux,
son taux de précision dépasse les 90 % daprès ses concepteurs
Le nombre de personnes atteintes et tuées par le nouveau coronavirus ne cesse daugmenter dans le monde (1,2 million de cas et 69 500 décès). Actuellement, la lutte contre cette maladie passe aussi par lutilisation de lintelligence artificielle. Les acteurs du secteur arrivent en effet à mettre au point plusieurs outils permettant notamment doptimiser le suivi des malades ou la désinfection des zones contaminées, la recherche pharmaceutique ou le dépistage. Sur ce dernier point, une équipe de chercheurs des universités de lOklahoma (États-Unis), de Kharkiv (Ukraine) et du Michigan (États-Unis) ont pu créer une application mobile censée aider au diagnostic du coronavirus grâce à lanalyse du son de la toux de lutilisateur.
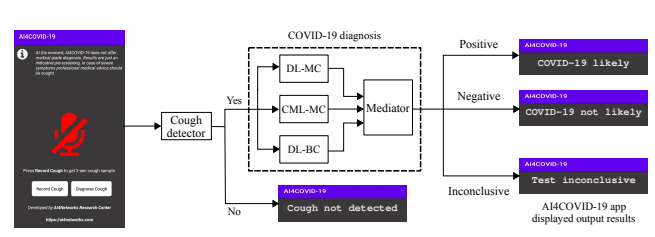
Nommée AI4COVID-19, lapplication réalise un enregistrement de la toux du sujet qui dure 2 secondes. Ensuite, elle analyse les échantillons sonores grâce à un moteur dIA fonctionnant dans le Cloud avant de renvoyer un diagnostic préliminaire en une minute. À part la rapidité du test, les scientifiques revendiquent que son taux de précision est supérieur à 90 %.
« Les analyses basées sur lIA des radiographies et des tomodensitogrammes du système respiratoire ont montré quil est possible dexploiter les différences dans les altérations pathomorphologiques causées par le COVID-19 pour effectuer un diagnostic différentiel entre linfection bactérienne, linfection virale non COVID-19 et linfection virale COVID-19, avec une précision remarquable », constatent les chercheurs, dans un rapport publié dans la plateforme arXiv.
« Cela implique que le COVID-19 affecte le système respiratoire de manière assez distincte par rapport aux autres infections respiratoires. Il est donc logique démettre lhypothèse que les ondes sonores de la toux produites par le système respiratoire infecté par le COVID-19 présentent également des caractéristiques latentes uniques et que le risque de chevauchement de ces caractéristiques avec celles associées à dautres infections respiratoires est faible », ajoutent-ils.
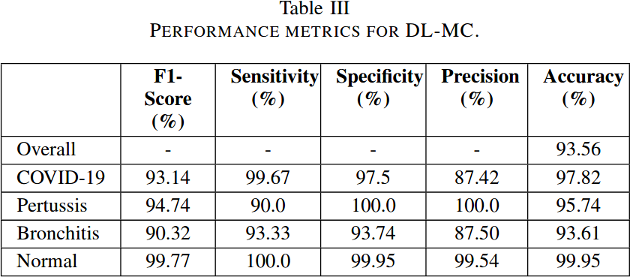
Les chercheurs ont ensuite intégré un détecteur de toux dans leur moteur dIA, qui est capable de distinguer le son de 50 bruits autres ambiants courants. Pour former et tester le système de diagnostic, ils ont collecté plusieurs enregistrements : 48 COVID-19, 102 bronchites, 131 coqueluches et 76 quintes de toux normales.
Si le son de la toux est détecté par lapplication, il est transmis à trois systèmes de classification parallèles et indépendants : le classificateur multi-classes basé sur lapprentissage en profondeur (DL-MC), le classificateur multi-classes basé sur lapprentissage machine classique (CML-MC) et le classificateur binaire basé sur lapprentissage en profondeur (DL-BC). Les résultats des trois classificateurs sont alors transmis à un médiateur. Si les classificateurs ne sont pas daccord, lapplication affiche que le test nest pas concluant. Dans le cas contraire, les trois classificateurs vont utiliser des approches différentes qui feront lobjet dune validation croisée qui aboutira à deux résultats (positif ou négatif).
« Malgré ses performances impressionnantes, AI4COVID-19 n'est pas destiné à rivaliser avec les tests cliniques. Au contraire, il offre un outil fonctionnel unique pour surveiller, tracer, suivre et, surtout, contrôler en temps utile, de manière rentable et sûre, la propagation rampante de la pandémie mondiale en permettant virtuellement le dépistage pour tous. Alors que nous travaillons à l'amélioration de l'AI4COVID-19, ce rapport a pour but de présenter une validation de principe afin d'encourager les essais cliniques et le soutien de la communauté pour des données plus étiquetées », conclut toutefois l'équipe de chercheurs.
Source : arXiv
Et vous ?
Que pensez-vous de cette application ?
Voir aussi :
 Répondre avec citation
Répondre avec citation













Partager