














235 millions de profils d'utilisateurs dInstagram, TikTok et YouTube ont été exposés dans une fuite massive de données,
Social Data, la société à lorigine de la fuite, a fermé la base de données
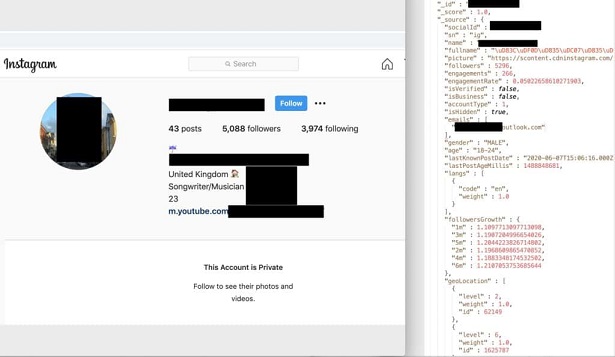
Quelque 235 millions de profils d'utilisateurs d'Instagram, YouTube et TikTok, compilés par une société de marketing de données sur des médias sociaux, ont été trouvés en ligne dans une base de données exposée au public, selon un nouveau rapport de léquipe de chercheurs de Comparitech dirigée par Bob Diachenko. Les données, extraites de profils publics, comprennent des noms d'utilisateurs, des noms complets, des coordonnées, des images, des statistiques sur les followers, l'âge, le sexe et plusieurs autres détails. Le grattage (scraping) de données est cependant strictement contraire aux conditions d'utilisation de la plupart des réseaux sociaux.
Découverte le 1er août par Bob Diachenko et rendue publique mercredi, la base de données ne nécessitait pas de mot de passe ou toute autre forme dauthentification pour y accéder, selon le rapport des chercheurs de Comparitech. Les données étaient réparties sur plusieurs ensembles, les plus importants étant deux ensembles d'un peu moins de 100 millions de profils chacun et contenant des enregistrements de profils apparemment grattés à partir d'Instagram. Le troisième plus important était un ensemble de données de quelque 42 millions d'utilisateurs de TikTok, suivi par un autre dun peu moins de 4 millions de profils d'utilisateurs de YouTube.
Le rapport indique que, d'après les échantillons que les chercheurs ont collectés, un enregistrement sur cinq contenait soit un numéro de téléphone soit une adresse électronique. En plus du fait que chaque enregistrement contenait au moins une partie, parfois la totalité, des informations sur les profils utilisateurs, la base de données exposait également, des statistiques sur l'engagement des "followers", notamment : nombre de "followers" ; taux d'engagement ; taux de croissance du public des "followers" ; genre, âge et localisation du public ; les "Likes" et autres.
« Ces informations seraient probablement très utiles aux spammeurs et aux cybercriminels qui mènent des campagnes de phishing », a déclaré Paul Bischoff, rédacteur en chef de Comparitech. « Même si les données sont accessibles au public, le fait qu'elles aient été divulguées sous forme agrégée en tant que base de données bien structurée les rend beaucoup plus précieuses que chaque profil ne le serait isolément », ajoute Bischoff. En effet, il serait facile pour un bot d'utiliser la base de données pour poster des spams commentaires ciblés sur tout profil Instagram correspondant à des critères tels que le sexe, l'âge ou le nombre de "followers", a-t-il ajouté.
« Nous ne savons pas combien de temps les données ont été exposées avant notre découverte le 1er août, ni si des parties non autorisées y ont eu accès pendant l'exposition. Nos expériences sur le "honeypot" (pot de miel) montrent que les pirates peuvent trouver et attaquer des bases de données non sécurisées dans les heures qui suivent leur exposition. La base de données a toutefois été fermée environ trois heures après la divulgation initiale.
Une série de rapports publiés récemment ont fait état de la divulgation de données utilisateurs, souvent sensibles, dans les comptes exposés. Un rapport publié mercredi par Secure Thoughts disait que 2,5 millions d'enregistrements qui semblaient contenir des données médicales sensibles et des PII (Personal Identifiable Information) avaient été découverts exposés sans protection par le chercheur en sécurité Jeremiah Fowler le 7 juillet. Les dossiers, qui comprenaient des noms, des dossiers d'assurance, des notes de diagnostic médical et bien plus encore, faisaient référence à une société d'intelligence artificielle appelée Cense.
Un autre rapport publié en juillet par l'équipe de Digital Shadows a révélé quil y avait 15 milliards de données de connexion volées qui seraient en vente sur le dark Web. Le rapport a indiqué que ces données ont pu être dérobées à partir de 100 000 violations et comprennent des paires de nom d'utilisateur et de mot de passe de sécurité pour les comptes de médias sociaux, les services de streaming musical, et même les services bancaires en ligne. Mais ces données pourraient avoir été obtenues dans des bases de données accessibles librement sur Internet.
Les données auraient été compilées par Social Data, une société qui vend des données sur les utilisateurs des médias sociaux
Après la divulgation de leur découverte, léquipe de Bob Diachenko a pu retracer la base de données jusquà Social Data, une société enregistrée à Hong Kong et qui vend des données sur les influenceurs des médias sociaux aux spécialistes du marketing. Diachenko a initialement lié les données à Deep Social, une société aujourd'hui fermée, qui a été interdite par Facebook et Instagram de leurs interfaces de programmation d'applications marketing en 2018, avec une menace de poursuites judiciaires si elle continuait à gratter les données des profils utilisateur. Les chercheurs suggèrent que les preuves, y compris les noms des ensembles de données, désignent une société appelée Deep Social.
Une fois que les chercheurs ont trouvé la base de données et les indices sur son origine, « nous avons envoyé une alerte à Deep Social, en supposant que les données leur appartenaient », a expliqué Bischoff. Les administrateurs de Deep Social ont ensuite transmis la divulgation à Social Data. « Social Data a fermé la base de données environ trois heures après notre premier e-mail », a ajouté Bischoff.
Un porte-parole de Facebook a déclaré que « gratter les informations des utilisateurs d'Instagram est une violation claire de nos politiques. Nous avons révoqué l'accès de Deep Social à notre plateforme en juin 2018 et envoyé un avis juridique interdisant toute nouvelle collecte de données ». Social Data nie avoir des liens avec Deep Social et nie également tout méfait dans la compilation des données, affirmant que « toutes les données sont disponibles gratuitement pour toute personne ayant accès à Internet ».
« Nous collectons des données et les enrichissons avec des informations supplémentaires utiles uniquement pour le compte de nos clients de bonne réputation, qui les utilisent strictement aux fins prévues. Il est extrêmement triste que cet incident se soit produit dû à un ensemble d'événements malheureux. Cependant, dès que nous avons eu connaissance de l'incident, nous l'avons immédiatement résolu. Depuis lors, nous avons travaillé en étroite collaboration avec les experts en sécurité de l'information pour auditer notre infrastructure de sécurité et augmenter les niveaux de sécurité de l'information requis afin d'éviter que des incidents similaires ne se reproduisent à l'avenir », a expliqué un porte-parole de Social Data dans une déclaration.
Bien que Social Data insiste pour dire quil ne gratte que ce qui est accessible au public, cette pratique est contraire aux conditions d'utilisation de Facebook, Instagram, TikTok et YouTube. Selon Bischoff, les robots de "scraping" automatisé peuvent être difficiles à distinguer des visiteurs normaux des sites Web, de sorte que les sociétés de médias sociaux ont du mal à les empêcher d'accéder aux profils des utilisateurs avant qu'il ne soit trop tard.
Chloé Messdaghi, vice-présidente de la stratégie de la société de cybersécurité chez Point3 Security a expliqué, dans une déclaration suite au rapport, que le "scraping" est essentiellement l'utilisation d'informations personnelles sans autorisation à des fins de profit. « C'est un acte qui va à l'encontre du droit à la vie privée de l'individu et qui expose tous ceux dont les données sont impliquées à un risque accru d'attaque de la part des attaquants par phishing », a-t-elle déclaré. « Les sociétés de "scraping" de données soutiennent, peut-être involontairement, des acteurs malveillants et permettent aux cybercriminels de faire ce qu'ils font ».
C'est à peu près le même problème que les questions de vie privée liées à la reconnaissance faciale sans autorisation, a-t-elle ajouté. « Lorsque nous voyons les effets effrayants de l'utilisation potentiellement abusive de ces technologies contre des militants dans des endroits comme Biélorussie et Hong Kong, cela devrait nous faire réfléchir et servir d'appel à l'action du Congrès », a-t-elle déclaré. « Il est clair que lorsqu'il s'agit de "scraping", les données personnelles que nous confions à une plateforme ne restent pas sur cette plateforme - malgré les politiques propres au site Web ».
Les utilisateurs concernés d'Instagram, de TikTok et de YouTube devraient être particulièrement attentifs aux arnaques de phishing par courrier électronique ou par le biais de commentaires sur les médias sociaux, même si les chercheurs nont pas de preuves que les données ont été téléchargées par des cybercriminels.
Source : Comparitech
Et vous ?
Quen pensez-vous ?
Voir aussi :

 Répondre avec citation
Répondre avec citation
Partager