














Git 2.33 est disponible, avec un nouveau processus de fusion optionnel, il est 9 000 fois plus rapide
et apporte un nouveau backend de stratégie de fusion
Léquipe du projet open source annonce la sortie de Git 2.33 avec des fonctionnalités et des corrections de bogues provenant de plus de 74 contributeurs. « La version 2.33 ne comporte pas beaucoup de changements et de nouvelles fonctionnalités pour l'utilisateur final », à part des corrections et des améliorations internes. Cependant, mais il y a un changement majeur, décrit comme un « nouveau backend de stratégie de fusion ». La stratégie en question est merge-ort, où "ort" signifie Ostensibly Recursive's Twin, selon son créateur Elijah Newren.
Rappelons quune stratégie de fusion est le mécanisme utilisé pour combiner le code de plusieurs versions d'une même base de code. La fusion est une caractéristique essentielle des systèmes de contrôle de version distribués, car elle évite de devoir verrouiller une version principale lorsqu'une copie extraite est en cours de modification. Les mécanismes de fusion fonctionnent en comparant le contenu d'un fichier avec le contenu de son ancêtre, afin d'identifier les sections modifiées, puis en comparant les sections modifiées d'un fichier avec celles d'un autre. Voici, ci-dessous, un aperçu des fonctionnalités et des changements les plus intéressants :
Repiquage géométrique
Dans un précédent billet de blog, léquipe du projet open source Git a expliqué comment GitHub utilisait un nouveau mode de git repack pour mettre en uvre les tâches de maintenance des dépôts. Dans Git 2.32, beaucoup de ces correctifs ont été publiés dans le projet open-source Git. Historiquement, git repack faisait l'une des deux choses suivantes : soit il repackait tous les objets libres dans un nouveau paquet (en supprimant éventuellement les copies libres de chacun de ces objets), soit il repackait tous les paquets ensemble dans un seul nouveau paquet (en supprimant éventuellement les paquets redondants).
D'une manière générale, Git est plus performant lorsqu'il y a moins de paquets, car de nombreuses opérations évoluent avec le nombre de paquets dans un dépôt. C'est donc souvent une bonne idée de tout regrouper en un seul pack. Mais historiquement parlant, les dépôts très fréquentés exigent souvent que tout leur contenu soit regroupé dans un seul et énorme pack. Cela s'explique par le fait que les bitmaps d'accessibilité, qui constituent une optimisation critique pour les performances de Git côté serveur, ne peuvent décrire que les objets d'un seul pack. Ainsi, si vous souhaitez utiliser des bitmaps pour couvrir efficacement de nombreux objets dans votre référentiel, ces objets doivent être stockés ensemble dans le même pack.
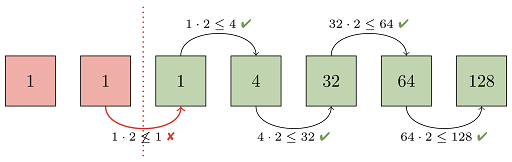
Léquipe du projet open source Git travaille à la suppression de cette limitation (vous pouvez en savoir plus sur la façon dont nous avons procédé), mais une étape importante est la mise en uvre d'un nouveau schéma de repacking qui permet de concilier un nombre relativement faible de packs et le regroupement des objets récemment ajoutés (en d'autres termes, l'approximation des nouveaux objets ajoutés depuis le repack précédent). Pour ce faire, Git a appris une nouvelle stratégie de reconditionnement « géométrique ». L'idée est de déterminer un ensemble (assez petit) de paquets qui pourraient être combinés ensemble de sorte que les paquets restants forment une progression géométrique basée sur la taille des objets. En d'autres termes, si le plus petit paquet contient N objets, le plus grand paquet suivant doit contenir au moins 2N objets, et ainsi de suite, en doublant (ou en augmentant d'une constante arbitraire) à chaque étape. Voici, un exemple pour mieux comprendre comment cela fonctionne. Tout d'abord, Git ordonne tous les paquets (représentés ci-dessous par un carré vert ou rouge) par ordre croissant en fonction du nombre d'objets qu'ils contiennent (les chiffres à l'intérieur de chaque carré). Ensuite, les paquets adjacents sont comparés (en commençant par les plus grands paquets et en allant vers les plus petits) pour s'assurer qu'il existe une progression géométrique :
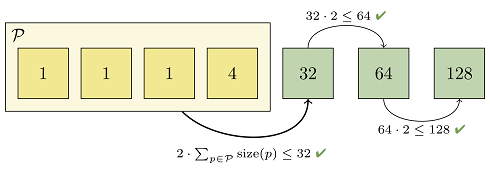
Ici, la progression est interrompue entre le deuxième et le troisième pack. Cela est dû au fait que ces deux packs contiennent chacun le même nombre d'objets (dans ce cas, un seul). Git décide alors qu'au moins les deux premiers packs seront contenus dans un nouveau pack destiné à rétablir la progression géométrique. Il doit ensuite déterminer combien de paquets plus grands doivent également être roulés afin de maintenir la progression :
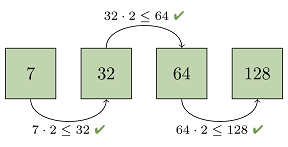
En combinant les deux premiers paquets, on obtiendrait deux objets, qui seraient encore trop grands pour s'insérer dans la progression (puisque le plus grand paquet suivant ne contient qu'un seul objet). Mais il suffit de rouler les quatre premiers paquets, car le cinquième paquet contient plus de deux fois plus d'objets que les quatre premiers paquets réunis :
Vous pouvez essayer vous-même en comparant les tailles des paquets sur un référentiel sur votre ordinateur portable avant et après le repacking géométrique avec le script suivant :
Léquipe du projet open source a également contribué aux correctifs pour écrire le nouveau format d'index inverse sur disque pour les index multi-pack. Ce format sera finalement utilisé pour alimenter les bitmaps multi-pack en permettant à Git de faire correspondre les positions des bits aux objets dans un index multi-pack. Ensemble, ces deux fonctionnalités permettront de couvrir les objets des paquets résultants avec un bitmap d'accessibilité, même s'il reste plus d'un paquet. Ces correctifs sont encore en cours d'élaboration et de révision, mais attendez-vous à une mise à jour de notre part lorsqu'ils seront incorporés dans une version.
Code : Sélectionner tout - Visualiser dans une fenêtre à part
2
3
4
5
6
7
8
9
10$ packsizes() { find .git/objects/pack -type f -name '*.pack' | while read pack; do printf "%7d %s\n" \ "$(git show-index < ${pack%.pack}.idx | wc -l)" "$pack" done | sort -rn } $ packsizes # before $ git repack --geometric=2 -d $ packsizes # after
merge-ort : une nouvelle stratégie de fusion
Lorsque Git effectue une fusion entre deux branches, il utilise l'une des nombreuses "stratégies" pour résoudre les changements. La stratégie originale est simplement appelée resolve et effectue une fusion standard à trois voies. Mais cette stratégie par défaut a été remplacée au début de l'histoire de Git par merge-recursive, qui présentait deux avantages importants :
- dans le cas de fusions "entrecroisées" (où il n'y a pas un seul point commun de divergence entre deux branches), la stratégie de fusion est la suivante point commun de divergence entre deux branches), la stratégie consiste à effectuer une série de fusions (de manière récursive, d'où son nom) pour chaque base possible. Cela permet de résoudre les cas pour lesquels la stratégie resolve produirait un conflit ;
- elle détecte les renommages de fichiers le long de chaque branche. Un fichier qui a été modifié d'un côté, mais renommé de l'autre, verra ses modifications seront appliquées à la destination renommée (plutôt que de produire un conflit très déroutant).
merge-recursive a bien servi comme valeur par défaut de Git pendant de nombreuses années, mais il avait quelques défauts. Il a été écrit à l'origine comme un script Python externe qui utilisait les commandes de plomberie de Git pour examiner les données. Il a ensuite été réécrit en C, ce qui a permis de gagner en rapidité. Mais l'organisation de son code et ses structures de données reflétaient toujours ses origines : il fonctionnait toujours principalement sur l'" index " de Git (la zone sur le disque où les modifications sont collectées pour les nouveaux commits) et l'arbre de travail. Cela a donné lieu à plusieurs bogues au fil des ans autour de cas de coin délicats (par exemple, celui-ci ou certains de ceux-ci).
Les origines de merge-recursive ont également rendu plus difficiles l'optimisation et l'extension du code. Le temps de fusion n'est pas un goulot d'étranglement dans la plupart des flux de travail, mais il y a certainement des cas importants (en particulier impliquant des renommages) où merge-recursive pourrait être très lent. De même, le backend de fusion est utilisé pour de nombreuses opérations qui combinent deux ensembles de modifications. Une opération de cherry-pick peut effectuer une série de fusions, et l'accélération de celles-ci a un effet notable.
La stratégie de fusion-ort est une réécriture from-scratch avec les mêmes concepts (récursion et détection des renommages), mais en résolvant de nombreux problèmes de correction et de performance de longue date. Le résultat est beaucoup plus rapide. Pour une fusion (mais une fusion importante et délicate contenant de nombreux renommages), merge-ort gagne plus de 500 fois en vitesse. Pour une série de fusions similaires dans une opération de cherry-pick, le gain de vitesse est de plus de 9000x (parce que merge-ort est capable de mettre en cache et de réutiliser certains calculs communs aux fusions). Ces cas ont été sélectionnés comme particulièrement mauvais pour l'algorithme merge-recursive, mais dans nos tests de cas typiques, nous trouvons que merge-ort est toujours un peu plus rapide que merge-recursive. Le véritable avantage est que merge-ort est toujours aussi rapide alors que merge-recursive présente une variance élevée.
En plus de cela, le code résultant est plus propre et plus facile à utiliser. Il corrige certains bogues connus dans merge-recursive. Il est plus attentif à ne pas accéder aux parties non modifiées de l'arbre, ce qui signifie que les personnes travaillant avec des clones partiels devraient être en mesure de réaliser davantage de fusions sans avoir à télécharger des objets supplémentaires. Et parce qu'il ne s'appuie pas sur l'index ou l'arbre de travail lors de la fusion, il ouvrira de nouvelles opportunités pour des outils comme git log pour montrer les fusions (par exemple, une différence entre le résultat de la fusion vanilla et l'état final commit, qui montre comment l'auteur a résolu les conflits).
Le nouveau merge-ort est susceptible de devenir la stratégie par défaut dans une future version de Git. En attendant, vous pouvez l'essayer en exécutant git merge -s ort ou en définissant votre configuration pull.twohead sur ort (malgré le nom, ceci est utilisé pour toute fusion, pas seulement pour git pull). Vous ne verrez peut-être pas encore toutes les accélérations ; certaines d'entre elles nécessiteront des changements dans d'autres parties de Git (par exemple, rebase aidant à passer les données mises en cache entre chaque fusion individuelle). Selon notre style habituel, nous aimons couvrir en détail deux ou trois éléments des versions récentes, puis une douzaine de sujets plus petits, moins détaillés. Maintenant que nous avons réglé le premier point, voici une sélection de changements intéressants dans Git 2.32 et 2.33 :
Vous avez peut-être utilisé git rev-list pour piloter la machinerie de traversée de l'historique de Git. Cela peut être vraiment utile lors de l'écriture de scripts, surtout si vous avez besoin de lister les commits/objets entre deux points extrêmes de l'historique. git rev-list possède un drapeau --pretty très pratique qui lui permet de formater les commits qu'il rencontre. Le paramètre --pretty peut afficher des informations sur un commit (comme son auteur, sa date de création, son hachage, des parties de son message, etc.). Mais cela peut être difficile à utiliser lors de l'écriture de scripts. Disons que vous voulez la liste des jours où vous avez écrit des commits. Vous pourriez penser à exécuter quelque chose comme :
Code : Sélectionner tout - Visualiser dans une fenêtre à part
2
3
4
5
Source : GitHub
Et vous ?
Quel est votre avis sur le sujet ?
Voir aussi :
 Répondre avec citation
Répondre avec citation
Partager