












AWS se plante une fois de plus, quelques jours après une panne massive
entraînant l'arrêt de services très sollicités tels que Twitch, Zoom, Slack et Xbox Live
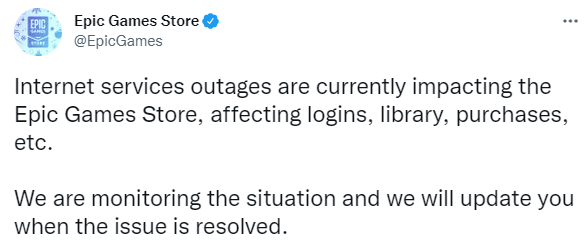
Amazon Web Service (AWS) a connu une nouvelle panne ce mercredi 15 décembre, rendant brièvement inaccessible une partie du Web. De nombreux services professionnels basés sur AWS, tels que Duo, le service de sécurité des points de terminaison à authentification à deux facteurs, Zoom, la plateforme de vidéoconférence, et Slack, le service de messagerie, ont été affectés. Les services de divertissement, notamment Hulu, Xbox Live et Halo, sont également tombés en panne. Le site DownDetector a également montré qu'AWS avait connu un pic de défaillance plus tôt dans la journée du mardi.
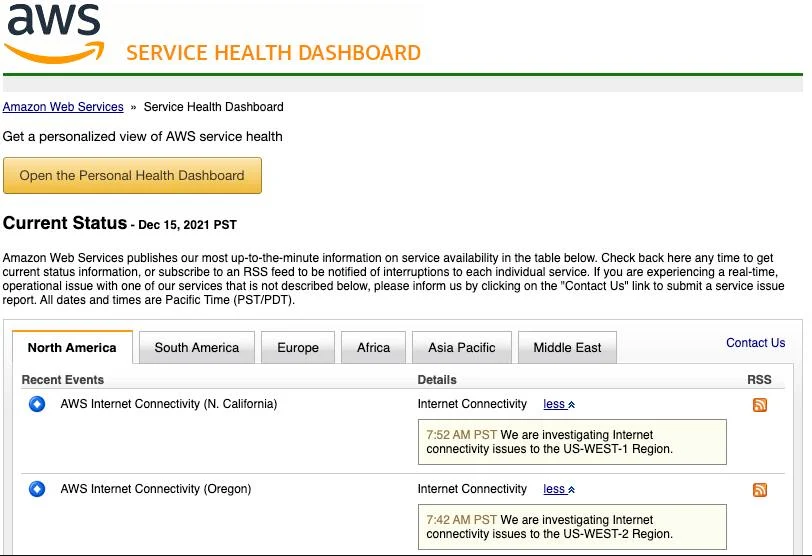
AWS, le leader mondial du cloud computing, vient de connaître deux pannes majeures en l'espace de deux semaines. La panne d'hier a commencé vers 7h43 PST (Pacific Standard Time), soit vers 16h43 à Paris, et a affecté les régions US-WEST-1 et US-WEST-2. Après que les utilisateurs ont commencé par signaler des problèmes de connectivité, AWS a finalement admis sur sa page d'état à 7h48 PST (16h48 à Paris) que sa région US-WEST-2 connaissait des problèmes de connectivité, et de même pour US-WEST-1 à 7h52 PT (16h52 à Paris). Dix minutes plus tard, l'entreprise a déclaré qu'elle avait trouvé la cause de la perte de connectivité des régions.
Elle a ajouté qu'elle avait apporté quelques corrections et qu'elle constatait une certaine reprise. Puis à 08h10 PST (17:10 à Paris), elle a déclaré : « nous avons résolu le problème affectant la connectivité Internet de la région US-WEST-1. La connectivité au sein de la région n'a pas été affectée par cet événement. Le problème a été résolu et le service fonctionne normalement ». Il en a été de même pour US-WEST-2 quatre minutes plus tard. La durée totale de la panne a été d'environ 30 minutes. La déclaration ci-dessus suggère que les connexions entrantes et sortantes de la région avec le reste du monde ont été affectées.
Elle suggère également que la mise en réseau au sein de la région était correcte. La cause exacte n'a pas été précisée. Il se peut qu'un technicien négligent ait trébuché sur un câble, qu'un ISP (Internet service provider) de la dorsale ait eu des problèmes quelque part, ou que ce soit le DNS. Les effets de ce temps d'arrêt se sont rapidement propagés sur Internet : les gens ont remarqué que les sites Web et les applications hébergés par Amazon ne fonctionnaient plus comme prévu. De nombreux services en ligne ont été affectés, notamment Twitch, Zoom, PSN, Xbox Live, Doordash, Quickbooks Online et Hulu.
La page d'état du géant du Web est devenue de moins en moins réactive, car les internautes ont afflué vers elle pour savoir ce qu'il était advenu de leurs services ou les choses chez AWS sont devenues de plus en plus bancales. De plus, cette panne survient après une autre panne massive d'AWS au début du mois affectant la région US-EAST-1, qui fournit la connectivité aux personnes et aux entreprises de la partie nord-est des États-Unis. En conséquence, le streaming via Netflix, Roku et Amazon Prime a été immédiatement affecté. Les appareils Ring ont également été mis hors service et sont devenus inaccessibles.
Les employés d'Amazon chargés de la livraison ont également déclaré qu'ils ne pouvaient pas accéder aux applications internes nécessaires pour scanner les colis, accéder aux itinéraires de livraison ou voir les horaires à venir. Comme AWS l'a expliqué par la suite, cet incident a été causé par une "activité automatisée visant à augmenter la capacité de l'un des services AWS hébergés sur le réseau AWS principal" qui "a entraîné une forte augmentation de l'activité de connexion. Cela a submergé les dispositifs de mise en réseau entre le réseau interne et le réseau AWS principal".
Selon les analystes, le moment est mal choisi pour le géant du cloud, qui a aussi travaillé d'arrache-pied au cours de la semaine écoulée pour corriger ses composants affectés par la vulnérabilité d'exécution de code à distance Apache Log4j (CVE-2021-44228), à en juger par le dernier bulletin de sécurité d'Amazon à ce sujet. Les pannes d'AWS, même brèves, rappellent à quel point les applications, les sites Web et les services d'aujourd'hui dépendent de plateformes uniques comme AWS. Par ailleurs, le site de détection des pannes DownDetector a montré que les sites de Salesforce et Facebook ont également été affectés par la panne d'hier.
Sources : Page d'état des services d'AWS, Rapports (1, 2)
Et vous ?
Quel est votre avis sur le sujet ?
Voir aussi

 Répondre avec citation
Répondre avec citation




Partager