














Google annonce des machines virtuelles Cloud TPU pour les charges de travail d'IA,
conçu pour exécuter des modèles d'apprentissage automatique avec des services d'IA sur Google Cloud
Au début de l'année dernière, les VM TPU sur Google Cloud ont été introduites pour faciliter l'utilisation de l'unité de traitement Tensor (TPU) en fournissant un accès direct aux machines hôtes TPU. « Aujourd'hui, nous sommes heureux d'annoncer la disponibilité générale (GA) des TPU VMs », déclare Google. La disponibilité générale des machines virtuelles Cloud TPU signifie que les utilisateurs ne doivent plus accéder à distance à Cloud TPU.
L'apprentissage automatique a permis des percées dans le monde des affaires et de la recherche, allant de la sécurité des réseaux aux diagnostics médicaux. Google a créé TPU afin de permettre à quiconque de réaliser des avancées similaires. Le TPU est l'ASIC d'apprentissage automatique personnalisé qui équipe les produits Google tels que Translate, Photos, Search, Assistant et Gmail.
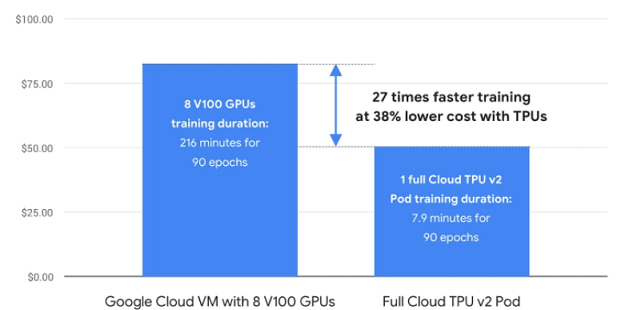
Cloud TPU est conçu pour exécuter des modèles d'apprentissage automatique de pointe avec des services d'IA sur Google Cloud. Et son réseau haut débit personnalisé offre plus de 100 pétaflops de performance dans un seul pod. Une puissance de calcul suffisante pour transformer une entreprise ou créer la prochaine percée de la recherche.
« L'accès direct aux machines virtuelles TPU a complètement changé ce que nous sommes capables de construire sur les TPU et a considérablement amélioré l'expérience des développeurs et les performances des modèles », Aidan Gomez, cofondateur et PDG, Cohere.
Avec les cloud TPU VM en, il est possible de travailler de manière interactive sur les mêmes hôtes que ceux auxquels le matériel TPU physique est attaché. Notre communauté d'utilisateurs TPU, en pleine croissance, a adopté avec enthousiasme ce mécanisme d'accès, car il permet non seulement d'avoir une meilleure expérience de débogage, mais aussi de réaliser certaines configurations de formation, comme l'apprentissage par renforcement distribué, qui n'étaient pas réalisables avec l'architecture TPU Node (réseaux accédés).
Nouveautés de la version GA
Les TPU Cloud sont désormais optimisés pour les charges de travail de recommandation à grande échelle.
- Les TPU peuvent offrir une vitesse d'apprentissage beaucoup plus rapide et des coûts d'apprentissage nettement inférieurs à ceux des CPU pour les modèles de systèmes de recommandation ;
- TensorFlow pour les TPU en nuage fournit une API puissante pour gérer de grandes tables d'incorporation et des recherches rapides ;
- Sur la tranche TPU v3-32, Snap a pu obtenir un débit ~3x supérieur (-67,3% de débit sur A100) avec un coût 52,1% inférieur par rapport à une configuration A100 équivalente (~4,65x perf/TCO).
Classement et recommandation
Avec la version TPU VMs GA, Google introduit la nouvelle API TPU Embedding, qui peut accélérer les charges de travail de classement et de recommandation basées sur le ML. De nombreuses entreprises sont aujourd'hui construites autour de cas d'utilisation de classement et de recommandation, tels que les recommandations audio/vidéo, les recommandations de produits (applications, commerce électronique) et le classement des publicités. Ces entreprises s'appuient sur des algorithmes de classement et de recommandation pour servir leurs utilisateurs et atteindre leurs objectifs commerciaux.
Au cours des dernières années, les approches de ces algorithmes ont évolué, passant d'une approche purement statistique à une approche basée sur les réseaux neuronaux profonds. Ces algorithmes modernes basés sur les réseaux neuronaux profonds offrent une meilleure évolutivité et une plus grande précision, mais ils ont un coût. Ils ont tendance à utiliser de grandes quantités de données et peuvent être difficiles et coûteux à former et à déployer avec une infrastructure ML traditionnelle.
L'intégration de l'accélération avec Cloud TPU peut résoudre ce problème à moindre coût. Les API d'intégration peuvent traiter efficacement de grandes quantités de données, comme les tableaux d'intégration, en répartissant automatiquement les données sur des centaines de puces Cloud TPU dans un pod, toutes connectées les unes aux autres via l'interconnexion personnalisée. Pour aider les utilisateurs à démarrer, Google publie les API de classement et de recommandation TF2, dans le cadre de la bibliothèque Tensorflow Recommenders.
Prise en charge des frameworks
La version GA de TPU VM prend en charge les trois principaux frameworks (TensorFlow, PyTorch et JAX) désormais proposés à travers trois environnements optimisés pour faciliter la configuration avec le framework respectif. La version GA a été validée avec TensorFlow v2-tf-stable, PyTorch/XLA v1.11 et JAX [0.3.6].
Caractéristiques spécifiques des TPU VMs
Les TPU VMs offrent plusieurs capacités supplémentaires par rapport à l'architecture TPU Node grâce à la configuration d'exécution locale, c'est-à-dire le matériel TPU connecté au même hôte que les utilisateurs exécutent la ou les charges de travail d'entraînement.
Exécution locale du pipeline d'entrée
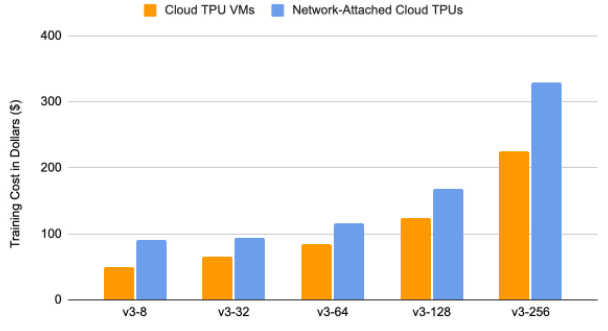
Le pipeline de données d'entrée s'exécute directement sur les hôtes TPU. Cette fonctionnalité permet d'économiser de précieuses ressources informatiques utilisées auparavant sous forme de groupes d'instances pour la formation distribuée PyTorch/JAX. Dans le cas de Tensorflow, la configuration de la formation distribuée ne nécessite qu'une seule VM utilisateur et le pipeline de données est exécuté directement sur les hôtes TPU. L'étude suivante résume la comparaison des coûts pour la formation de Transformer (FairSeq ; PyTorch/XLA) exécutée pour 10 époques sur une VM TPU par rapport à l'architecture TPU Node (TPU en réseau).
« Au cours des deux dernières années, Kakao Brain a développé de nombreux services et modèles d'IA révolutionnaires, notamment minDALL-E, KoGPT et, plus récemment, RQ-Transformer. Nous utilisons l'architecture TPU VM depuis son lancement sur Google Cloud, et nous avons constaté une amélioration significative des performances par rapport à la configuration originale des nuds TPU. Nous sommes très enthousiastes quant aux nouvelles fonctionnalités ajoutées dans la version générale disponible de TPU VM, telles que l'API Embeddings », a déclaré Kim Il-doo, PDG de Kakao Brain.
Apprentissage par renforcement distribué avec les VM de TPU
L'exécution locale sur l'hôte avec l'accélérateur permet également des cas d'utilisation tels que l'apprentissage par renforcement distribué. Les travaux classiques dans ce domaine, tels que seed-RL, IMPALA et Podracer, ont été développés à l'aide de TPU en cloud.
« ..., nous soutenons que les besoins en calcul des systèmes d'apprentissage par renforcement à grande échelle sont particulièrement bien adaptés à l'utilisation des TPU Cloud , et plus précisément des TPU Pods : des configurations spéciales dans un centre de données Google qui comportent plusieurs dispositifs TPU interconnectés par des canaux de communication à faible latence », déclare Podracer de DeepMind.
Prise en charge des opérations personnalisées pour TensorFlow
Grâce à l'exécution directe sur TPU VM, les utilisateurs peuvent désormais construire leurs propres opérations personnalisées telles que TensorFlow Text. Grâce à cette fonctionnalité, les utilisateurs ne sont plus liés aux versions du runtime de TensorFlow.
Source : Google
Et vous ?
Quel est votre avis sur le sujet ?
Voir aussi :
 Répondre avec citation
Répondre avec citation
Partager