
Envoyé par
Meta
En tant qu'encyclopédie la plus populaire de tous les temps - avec quelque 6,5 millions d'articles - Wikipédia est la première étape par défaut dans la recherche d'informations de recherche, de documents de base ou d'une réponse à cette question lancinante sur la culture pop. Wikipédia peut vous dire que les scientifiques ont nommé une nouvelle espèce de champignon Spongiforma squarepantsii, d'après le personnage de dessin animé SpongeBob SquarePants, ou que le membre de la tribu Blackfeet Joe Hipp a été le premier Amérindien à concourir pour le titre mondial des poids lourds de la World Boxing Association.
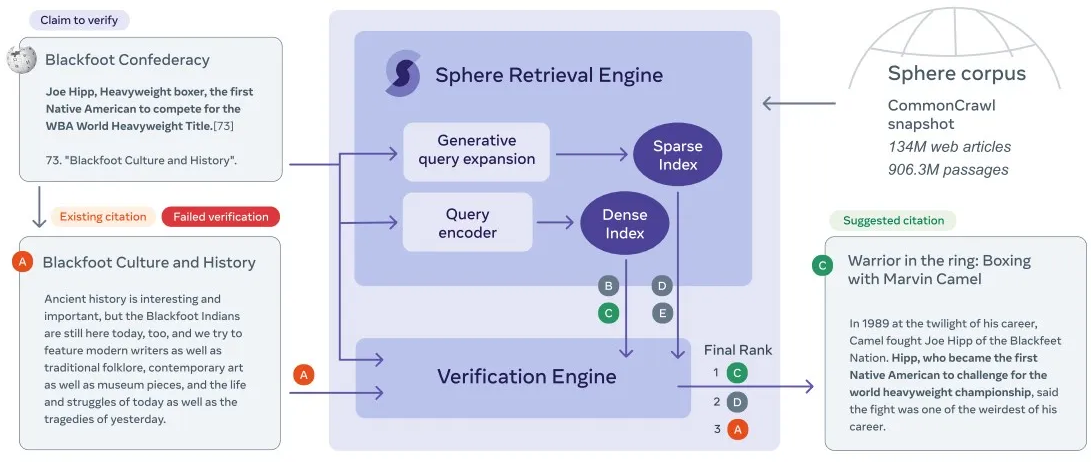
Mais parfois, cette recherche rapide d'informations s'accompagne d'un doute persistant*: comment savoir si ce que nous lisons est exact*? Par exemple, si vous aviez lu l'entrée mentionnée ci-dessus sur le membre de la tribu Blackfeet Joe Hipp il y a un mois, la citation de Wikipedia pour cette affirmation aurait été une page Web qui ne mentionnait même pas Hipp ou la boxe. Wikipédia est en crowdsourcing, il exige donc généralement que les faits soient corroborés ; les citations, les déclarations controversées et les documents controversés sur les personnes vivantes doivent inclure une citation. Les bénévoles revérifient les notes de bas de page de Wikipédia, mais, à mesure que le site continue de croître, il est difficile de suivre le rythme des plus de 17 000 nouveaux articles ajoutés chaque mois.
Les outils automatisés peuvent aider à identifier le charabia ou les déclarations sans citations, mais aider les éditeurs humains à déterminer si une source confirme réellement une affirmation est une tâche beaucoup plus complexe, qui nécessite la profondeur de compréhension et d'analyse d'un système d'IA.
En nous appuyant sur les recherches et les avancées de Meta AI, nous avons développé le premier modèle capable de scanner automatiquement des centaines de milliers de citations à la fois pour vérifier si elles soutiennent vraiment les affirmations correspondantes. Il est disponible en open-source, et vous pouvez voir une démo de notre vérificateur. En tant que source de connaissances pour notre modèle, nous avons créé un nouvel ensemble de données de 134 millions de pages Web publiques - un ordre de grandeur plus vaste et beaucoup plus complexe jamais utilisé pour ce type de recherches. Il attire l'attention sur les citations douteuses, permettant aux éditeurs humains d'évaluer les cas les plus susceptibles d'être défectueux sans avoir à passer au crible des milliers de déclarations correctement citées. Si une citation semble non pertinente, notre modèle suggérera une source plus applicable, pointant même vers le passage spécifique qui soutient la revendication. À terme, notre objectif est de créer une plate-forme pour aider les éditeurs de Wikipédia à repérer systématiquement les problèmes de citation et à corriger rapidement la citation ou à corriger le contenu de l'article correspondant à grande échelle.
"Il s'agit d'un exemple puissant d'outils d'apprentissage automatique qui peuvent aider à faire évoluer le travail des bénévoles en recommandant efficacement des citations et des sources précises. L'amélioration de ces processus nous permettra d'attirer de nouveaux éditeurs sur Wikipédia et de fournir des informations de meilleure qualité et plus fiables à des milliards de personnes dans le monde. J'attends avec impatience des améliorations continues dans ce domaine, d'autant plus que les outils d'apprentissage automatique sont capables de fournir des citations plus personnalisées et des options multilingues pour servir nos communautés Wikimedia dans plus de 300 langues".
Shani Evenstein Sigalov, chercheur à l'Université de Tel Aviv et wikimédien de longue date.
Enseigner aux machines à comprendre la relation entre des passages de texte complexes, tels que les entrées Wiki et les articles qu'elles citent, aidera également la communauté des chercheurs à faire progresser l'IA vers des systèmes plus intelligents capables de raisonner sur les connaissances du monde réel avec plus de complexité et de nuances.
Par exemple, pour remplacer la citation ratée sur Joe Hipp, notre système recommande un passage d'un article de 2015 dans le Great Falls Tribune*:
« En 1989, au crépuscule de sa carrière, [Marvin] Camel a combattu Joe Hipp de la Blackfeet Nation. Hipp, qui est devenu le premier Amérindien à se battre pour le championnat du monde des poids lourds, a déclaré que le combat était l'un des plus étranges de sa carrière ».
Pour identifier cette source, notre système a dû analyser une sémantique complexe. Le passage du journal ne mentionne pas explicitement la boxe, mais le modèle a déduit le contexte à partir d'indices indirects, tels que le terme poids lourd. Il a également compris que le mot défi dans l'article de Tribune signifie la même chose que rivaliser dans la revendication de Wikipedia.












Tester SIDE
 Répondre avec citation
Répondre avec citation






 )
)

Partager