PostgreSQL 15 est disponible, elle améliore de l'ordre de 25 % à 400 % ses algorithmes de tri en mémoire et sur disque,
et apporte la populaire commande MERGE
Le PostgreSQL Global Development Group annonce le 13 octobre la sortie de PostgreSQL 15, elle s'appuie sur les améliorations de performance des versions récentes avec des gains notables pour la gestion des charges de travail dans les déploiements locaux et distribués, notamment un tri amélioré. Cette version améliore l'expérience du développeur avec l'ajout de la populaire commande MERGE, et ajoute plus de capacités pour observer l'état de la base de données.
« La communauté des développeurs PostgreSQL continue de construire des fonctionnalités qui simplifient l'exécution des charges de travail de données à haute performance tout en améliorant l'expérience des développeurs », a déclaré Jonathan Katz, membre de la Core Team PostgreSQL. « PostgreSQL 15 montre comment, grâce au développement de logiciels ouverts, nous pouvons offrir à nos utilisateurs une base de données idéale pour le développement d'applications et sûre pour leurs données critiques. »
PostgreSQL, un système de gestion de données connu pour sa fiabilité et sa robustesse, bénéficie de plus de 25 ans de développement open source par une communauté mondiale de développeurs. Il sagit de l'un des systèmes de gestion des bases de données open source les plus avancés. Il est riche en fonctionnalités, avec des types de données robustes, une indexation puissante et un large éventail de fonctions intégrées que peuvent être utilisé pour simplifier la pile de données et permettre aux développeurs de se concentrer sur la création de son application. Postgres dispose de :
- une base de données relationnelle ;
- une base de données documentaire avec un support JSON complet ;
- un support géospatial ;
- partitionnement pour les données de séries chronologiques.
Voici, ci-dessous, les améliorations apportées à la cersion 15 de PostgreSQL
Amélioration des performances de tri et de la compression
Dans cette dernière version, PostgreSQL améliore ses algorithmes de tri en mémoire et sur disque, avec des benchmarks montrant des accélérations de 25 % à 400 % en fonction des types de données triées. L'utilisation de row_number(), rank(), dense_rank() et count() comme fonctions de fenêtre présente également des avantages en termes de performances dans PostgreSQL 15. Les requêtes utilisant SELECT DISTINCT peuvent maintenant être exécutées en parallèle.
En se basant sur le travail de la version précédente de PostgreSQL pour permettre les requêtes distantes asynchrones, le wrapper de données étrangères de PostgreSQL, postgres_fdw, supporte maintenant les commits asynchrones.
Les améliorations de performance de PostgreSQL 15 s'étendent à ses fonctions d'archivage et de sauvegarde. PostgreSQL 15 intègre le support de la compression LZ4 et Zstandard (zstd) aux fichiers WAL (write-ahead log), ce qui peut avoir des avantages en termes d'espace et de performance pour certaines charges de travail. Sur certains systèmes d'exploitation, PostgreSQL 15 intègre le support de la préextraction des pages référencées dans WAL pour aider à accélérer les temps de récupération. La commande de sauvegarde intégrée de PostgreSQL, pg_basebackup, supporte maintenant la compression côté serveur des fichiers de sauvegarde avec un choix de gzip, LZ4 et zstd.
La version 15 de PostgreSQL inclut la possibilité d'utiliser des modules personnalisés pour l'archivage, ce qui élimine la surcharge liée à l'utilisation d'une commande shell.
Fonctionnalités expressives pour les développeurs
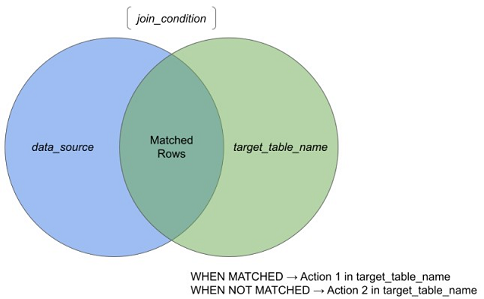
PostgreSQL 15 inclut la commande standard SQL MERGE. Elle permet d'écrire des instructions SQL conditionnelles qui peuvent inclure des actions INSERT, UPDATE et DELETE dans une seule instruction. Le graphique ci-dessous est une représentation simple de cette opération.
La logique métier, qui aurait autrement nécessité de nombreuses lignes de code (LOC), est simplifiée par cette instruction conditionnelle. En réduisant le nombre de LOC, on réduit également les coûts de maintenance à long terme. MERGE existe depuis un certain temps dans Oracle et SQL Server, et un avantage intéressant de l'implémentation dans PostgreSQL est qu'elle facilite le transfert du code SQL d'Oracle à PostgreSQL.
Cette dernière version ajoute de nouvelles fonctions permettant d'utiliser des expressions régulières pour inspecter les chaînes de caractères : regexp_count(), regexp_instr() regexp_like() et regexp_substr(). Elle étend également la fonction range_agg pour agréger les types de données à plages multiples, qui ont été introduits dans la version précédente.
La version 15 de PostgreSQL permet aux utilisateurs de créer des vues qui interrogent les données en utilisant les permissions de l'appelant, et non du créateur de la vue. Cette option, appelée security_invoker, ajoute une couche supplémentaire de protection pour s'assurer que les appelants de la vue ont les permissions correctes pour travailler avec les données sous-jacentes.
Amélioration de la réplication logique
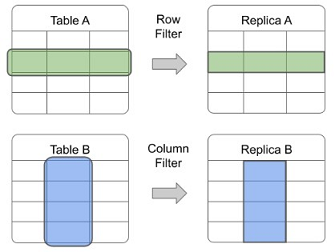
La réplication logique a été ajoutée au noyau de PostgreSQL dans la version 10. Depuis lors, elle a progressé à grands pas et a ajouté de nombreuses améliorations et fonctionnalités au noyau. Avant la version 10, la réplication logique ne pouvait être réalisée qu'avec l'aide de l'extension pglogical. PostgreSQL 15 offre plus de flexibilité pour gérer la réplication logique. Cette version introduit le filtrage des lignes et les listes de colonnes pour les éditeurs, permettant aux utilisateurs de choisir de répliquer un sous-ensemble de données d'une table.
PostgreSQL 15 intègre des fonctionnalités pour simplifier la gestion des conflits, notamment la possibilité de ne pas rejouer une transaction conflictuelle et de désactiver automatiquement un abonnement si une erreur est détectée. Cette version inclut également la prise en charge de l'utilisation du commit à deux phases (2PC) avec la réplication logique. Avec la version 15 de PostgreSQL, la réplication logique ajoute la fonctionnalité tant attendue des filtres de niveau ligne et colonne.
Réplication logique - Filtre de lignes et de colonnes
Améliorations de la journalisation et de la configuration
PostgreSQL 15 introduit un nouveau format de journalisation : jsonlog. Ce nouveau format produit des données de journalisation en utilisant une structure JSON définie, ce qui permet aux journaux PostgreSQL d'être traités dans des systèmes de journalisation structurés. Cette version donne aux administrateurs de bases de données plus de flexibilité dans la manière dont les utilisateurs peuvent gérer la configuration de PostgreSQL, en ajoutant la possibilité d'accorder aux utilisateurs la permission de modifier les paramètres de configuration au niveau du serveur. De plus, les utilisateurs peuvent maintenant rechercher des informations sur la configuration en utilisant la commande \dconfig à partir de l'outil de ligne de commande psql.
Autres changements notables
Les statistiques de niveau serveur de PostgreSQL sont désormais collectées dans la mémoire partagée, éliminant à la fois le processus de collecte des statistiques et l'écriture périodique de ces données sur le disque. La version 15 de PostgreSQL permet de faire d'une collation ICU (Le service de collation ICU permet de comparer des chaînes de caractères et prend en charge les ordres de tri appropriés pour chacune des zones dont lutilisateur a besoin) la collation par défaut pour un cluster ou une base de données individuelle.
Cette version ajoute également une nouvelle extension intégrée, pg_walinspect, qui permet aux utilisateurs d'inspecter le contenu des fichiers journaux en écriture directement depuis une interface SQL.
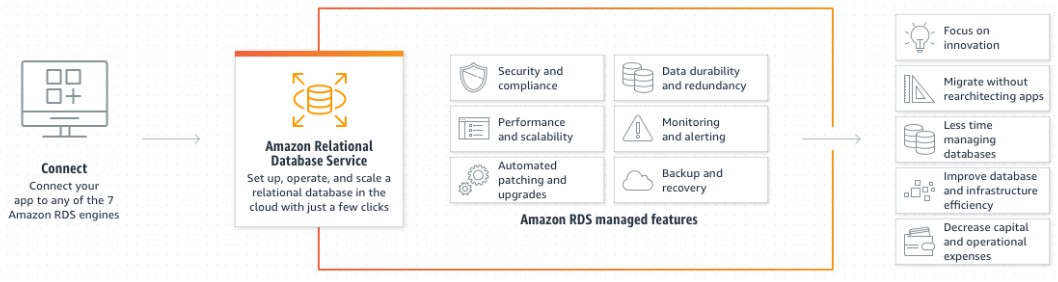
PostgreSQL 15 révoque également la permission CREATE de tous les utilisateurs, à l'exception du propriétaire de la base de données du schéma public (ou par défaut). Elle supprime à la fois le mode « sauvegarde exclusive », longtemps décrié, et le support de Python 2 dans PL/Python. Si la version 15 de PostgreSQL apporte des améliorations notables, il nen reste pas moins vrai que certaines attentes ne sont toujours pas comblées. À linstar dAmazon RDS (Amazon Relational Database Service) qui ne supporte pas la version 15 de PostgreSQL.
Amazon RDS est un service de base de données relationnelle distribuée proposé par Amazon Web Services (AWS). Il s'agit d'un service web fonctionnant « dans le cloud » et conçu pour simplifier la configuration, l'exploitation et la mise à l'échelle d'une base de données relationnelle destinée à être utilisée dans des applications. Les processus d'administration tels que l'application de correctifs au logiciel de base de données, la sauvegarde des bases de données et l'activation de la récupération ponctuelle sont gérés automatiquement.
Amazon RDS pour PostgreSQL prend en charge de nombreuses extensions pour le moteur de base de données PostgreSQL. La communauté PostgreSQL les appelle parfois des modules. Les extensions étendent la fonctionnalité fournie par le moteur PostgreSQL. Les utilisateurs du service de base de données dAmazon devront encore attendre que Postgres intègre cette modification dans son noyau.
Source : PostgreSQL Global Development Group
Et vous ?
 Quelles améliorations de PostgreSQL 15 vous intéresse le plus ?
Quelles améliorations de PostgreSQL 15 vous intéresse le plus ?
Quels manquements souhaiteriez-vous voir corriger sur PostgreSQL ?
À votre avis, PostgreSQL 15 peut-elle mieux apporter satisfaction que ses concurrents : Oracle, Microsoft SQL Server, MySQL ou encore Amazon Aurora ?
Quel SGBD preferez-vous le plus ? Pourquoi ?
Voir ausssi :
La majorité des serveurs PostgreSQL sur Internet ne seraient pas sécurisés, selon Jonathan Mortensen, alors qu'il est souvent considéré comme un système plus fiable et plus robuste que MySQL
PostgreSQL : Supabase annone la mise en libre accès de Postgres-wasm, un serveur PostgreSQL qui fonctionne dans un navigateur
PostgreSQL aurait commencé à travailler sur le support de la compression Zstandard, pour compléter toutes les possibilités de LZ4 que l'on trouve actuellement dans PostgreSQL 14
















 Répondre avec citation
Répondre avec citation























Partager