











Bonjour.
Je suis en train de corriger une table qui contient environ 10000 lignes. Il y a eu pas mal d'erreurs de saisie, ce qui fait qu'elle comporte un nombre important de doublons que je dois supprimer (la table n'avait pas de contrainte d'unicité).
VAC_ID (clé primaire auto-incrémentée)
VAC_DATE
D1_ID
D2_ID
Il ne doit y avoir qu'un seul "couple" D1_ID et D2_ID par VAC_DATE. J'ai donc créé cette requête pour trouver les doublons :
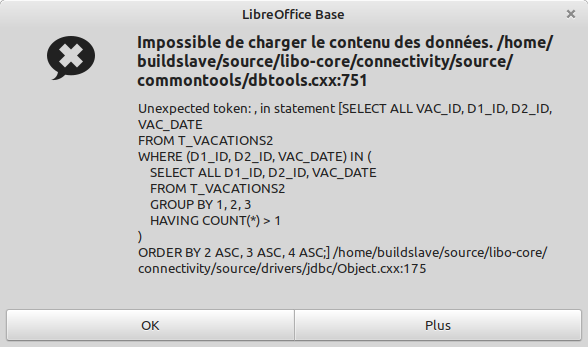
Elle fait le boulot mais comme il y a beaucoup de lignes à supprimer, j'aimerais savoir comment faire pour afficher également la colonne VAC_ID afin que je puisse créer un script pour supprimer en un clic tous les doublons (et même certains "triblons" et "quadrublons").
Code : Sélectionner tout - Visualiser dans une fenêtre à part
2
3
4
5
Merci.
 Répondre avec citation
Répondre avec citation















Partager