1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
|
from seleniumwire import webdriver
from selenium.webdriver.common.by import By
import time, requests, json, re, os
# crée et retourne le dossier de l'article
def mkdir(data):
cat = ""
for i in data["Classifications"]:
if i["ClassificationSystem"] == "ISO":
cat = i["TextLabelNoNorm"]
fab = data["COMPLabel"]
art = data["ArticleNumber"]
cab = data["Barcode"]
dir_name = cat + "__" + fab + "__" + art + "__" + cab
if not os.path.exists("./" + dir_name):
os.mkdir("./" + dir_name)
return dir_name
# Recupere les images jpg et png de l'article
def get_images(data):
imgs = dict()
for i in data["Mmss"].keys():
r = re.match(".*\.(jpg|png)", str(data["Mmss"][i]))
if r:
k = (
"https://www.toolsunited.com/Images/Component/"
+ data["Mmss"]["J3"]
+ "/"
+ re.search("...$", data["Mmss"][i]).group().upper()
+ "_"
+ data["Mmss"]["J3"]
+ "/"
+ data["Mmss"][i]
)
imgs[k] = imgs.get(k, 0) + 1
path = mkdir(data)
for i in imgs.keys():
img_data = requests.get(i).content
filename = re.sub(r"^.*/([^/]*)$", r"\1", i)
with open("./" + path + "/" + filename, "wb") as f:
f.write(img_data)
# initialise le pilote de firefox
driver = webdriver.Firefox()
driver.implicitly_wait(7)
driver.maximize_window()
# ouvre sur la recherche a scraper
# TODO modifier cette url en fonction des arguements
driver.get(
"https://www.toolsunited.com/App/EN/TuMenu/ShowResult?search=[[],%22Root%22,0,10,%22default%22,true,[],null]"
)
time.sleep(3)
# scrolling
driver.execute_script("window.scrollTo(0, document.documentElement.scrollHeight);")
# collecte les lignes du tableau de resultat de recherche
td_list = driver.find_elements(By.CSS_SELECTOR, "#gridForResultList tr")
# crée un iterateur d'id article
ids = iter([i.get_attribute("id") for i in td_list])
# composition fix de l'url json detail article
req_prefix = "https://www.toolsunited.com/App/FR/Article/GetJsonArticleDetails?article="
req_sufix = "&dataSource=toolsunited&FR-TU-71-5926-432d-8604-5bd11ccb9ab9-TrueTU"
# collecte json detail pour chaque article
end = object()
i = next(ids, end)
while i is not end:
url = req_prefix + i + req_sufix
res = requests.get(url)
if res.status_code == 200:
data = res.json()
path = mkdir(data)
with open("./" + path + "/" + i + ".json", "w") as f:
f.write(json.dumps(res.json(), indent=4))
i = next(ids, end)
get_images(data)
continue
elif res.status_code == 405:
# userid doit etre valider par un captcha
# si pas de captcha possibilité de ban :(
driver.get(
"https://www.toolsunited.com/App/FR/TuMenu/ShowResult?search=[[%22Volltext%C2%A7NWCW%22],%22Root%22,0,100,%22default%22,true,[],null]"
)
input("Valide captcha et press une touche pour continuer ...")
continue
else:
# autre status pas encore géré
print(res.status_code)
print(res.raise_for_status())
input("ENTER pour continuer !")
driver.quit() |











d'une ligne pour ouvrir la fenêtre "pop-up" avec les détails de l'outil... Bref, je galère pas mal du coup si quelqu'un pouvait me montrer comment collecter les détails sur une des lignes, cela m'aiderait pas mal à avancer.


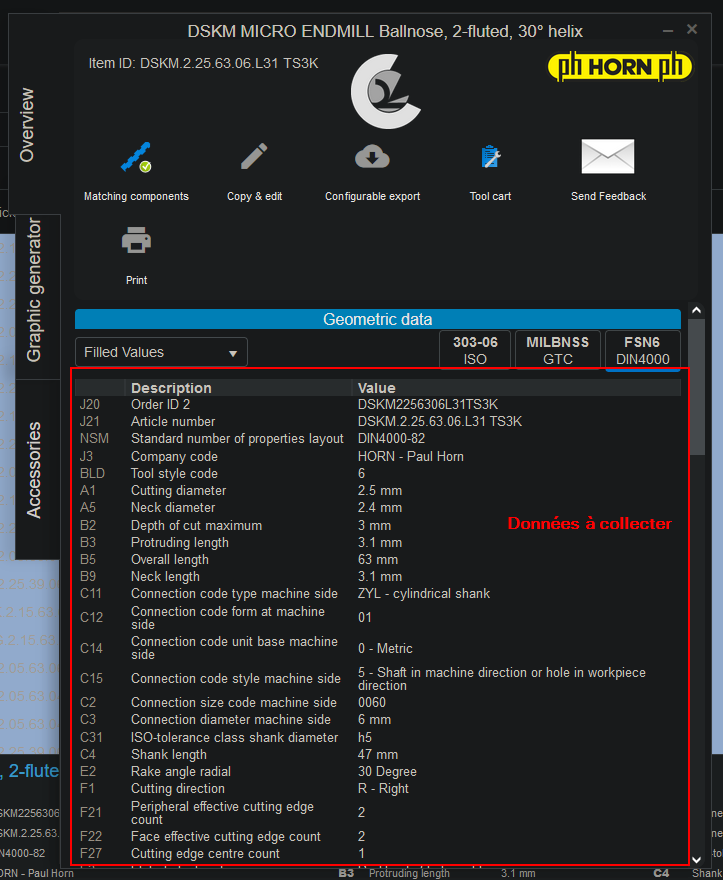
 Répondre avec citation
Répondre avec citation









Partager