
















Les affirmations de Google concernant son système basé sur l'apprentissage par renforcement sont à nouveau remises en question,
par une équipe de l'université de Californie à San Diego
En juin 2021, Google a annoncé avoir mis au point un système basé sur l'apprentissage par renforcement capable de générer automatiquement des plans optimisés de puces électroniques. Aujourd'hui, une équipe de l'université de Californie à San Diego (UCSD) remet en question les affirmations de Google concernant son modèle plus performant que celui des humains.
Ces plans déterminent la disposition des blocs de circuits électroniques à l'intérieur de la puce, c'est-à-dire l'emplacement des curs de l'unité centrale et du processeur graphique, de la mémoire et des contrôleurs de périphériques sur la matrice de silicium physique. La planification des puces est la tâche d'ingénierie consistant à concevoir l'agencement physique d'une puce informatique. Malgré cinq décennies de recherche, la planification des puces n'a pas été automatisée et nécessiterait des mois d'efforts intenses de la part des ingénieurs chargés de la conception physique pour produire des schémas manufacturables.
Des chercheurs ont présenté une approche d'apprentissage par renforcement profond pour la planification des puces. En moins de six heures, cette méthode génère automatiquement des plans de puce qui sont supérieurs ou comparables à ceux produits par les humains dans toutes les mesures clés, y compris la consommation d'énergie, la performance et la surface de la puce.
Pour y parvenir, les chercheurs considèrent la planification des puces comme un problème d'apprentissage par renforcement et développent une architecture de réseau neuronal convolutionnel graphique basée sur les arêtes, capable d'apprendre des représentations riches et transférables de la puce. En conséquence, la méthode des chercheurs utilise l'expérience passée pour devenir meilleure et plus rapide dans la résolution de nouvelles instances du problème, ce qui permet la conception de puces par des agents artificiels ayant plus d'expérience que n'importe quel concepteur humain.
La méthode a été utilisée pour concevoir la prochaine génération d'accélérateurs d'intelligence artificielle (IA) de Google et pourrait permettre d'économiser des milliers d'heures de travail humain pour chaque nouvelle génération. Google a déclaré qu'il utilisait ce système d'IA pour concevoir ses propres puces TPU qui accélèrent les charges de travail d'IA : il utilisait l'apprentissage automatique pour faire fonctionner plus rapidement ses autres systèmes d'apprentissage automatique.
Le plan d'une puce est important car il détermine les performances du processeur. Il convient d'agencer soigneusement les blocs de circuits de la puce pour que, par exemple, les signaux et les données se propagent entre ces zones à un rythme souhaitable. Les ingénieurs passent généralement des semaines, voire des mois, à peaufiner leurs conceptions afin de trouver la configuration optimale. Tous les différents sous-systèmes doivent être placés d'une certaine manière pour produire une puce aussi puissante, économe en énergie et petite que possible.
Aujourd'hui, la production d'un plan d'étage implique souvent un mélange de travail manuel et d'automatisation à l'aide d'applications de conception de puces. L'équipe de Google a cherché à démontrer que son approche d'apprentissage par renforcement produirait des meilleures conceptions que celles réalisées par des ingénieurs humains utilisant des outils industriels. De plus, Google a déclaré que son modèle accomplissait son travail beaucoup plus rapidement que des ingénieurs.
« En moins de six heures, notre méthode génère automatiquement des plans d'implantation de puces qui sont supérieurs ou comparables à ceux produits par des humains dans toutes les mesures clés », écrivent les Googlers dans leur article paru dans Nature.
Cette recherche a attiré l'attention de la communauté de l'automatisation de la conception électronique, qui s'orientait déjà vers l'intégration d'algorithmes d'apprentissage automatique dans ses suites logicielles. Aujourd'hui, une équipe de l'université de Californie à San Diego (UCSD) remet en question les affirmations de Google concernant son modèle plus performant que celui des humains.
Dirigé par Andrew Kahng, professeur d'informatique et d'ingénierie, ce groupe a passé des mois à rétroconcevoir le pipeline de planification des sols décrit par Google dans Nature. Le géant du web n'a pas divulgué certains détails du fonctionnement interne de son modèle, invoquant une sensibilité commerciale, de sorte que l'UCSD a dû trouver le moyen de fabriquer sa propre version complète pour vérifier les conclusions des Googlers. Il est à noter que le professeur Kahng a participé à l'examen de l'article de Google par la revue Nature.
Les universitaires ont finalement constaté que leur propre création du code original de Google, appelée circuit training (CT) dans leur étude, était moins performante que les humains utilisant les méthodes et outils traditionnels de l'industrie.
« Nous proposons une mise en uvre et une évaluation ouvertes et transparentes de l'approche d'apprentissage par renforcement profond de Google Brain pour le placement des macros et sa mise en uvre de l'apprentissage par circuit (CT) dans GitHub. Nous implémentons en open source des éléments clés de l'apprentissage par circuits et clarifions les divergences entre l'apprentissage par circuits et l'article de Nature », écrivent-ils
De nouveaux cas de test sur les outils ouverts sont développés et publiés. Les chercheurs évaluent CT avec de multiples macro-placeurs alternatifs, tous les flux d'évaluation et les scripts associés étant publiés dans GitHub. Les expériences englobent également des benchmarks académiques de placement de taille mixte, ainsi que des études d'ablation et de stabilité.
Plusieurs disparités importantes ont été constatées entre CT et Nature
- CT suppose que toutes les instances de la liste de réseaux d'entrée ont des emplacements (a, b), c'est-à-dire que la netlist a déjà été placée avant d'être introduite dans CT. Les informations relatives à l'emplacement sont utilisées par le processus de groupage, de quadrillage et de regroupement de CT. Toutefois, cela n'était pas évident lors de l'examen du document et n'est pas mentionné dans Nature. Les expériences montrent que le fait de disposer d'informations initiales sur l'emplacement peut améliorer de manière significative les résultats de l'examen comparatif ;
- La fonction de coût de substitution définit l'objectif qui guide l'apprentissage de l'agent RL. CT fixe le poids de congestion 𝜆 à 0,5 et le poids de densité 𝛾 à 1,0. Nature indique que « le poids d'encombrement 𝜆 est fixé à 0,01, le poids de densité 𝛾 est fixé à 0,01 ». Cependant, les ingénieurs de Google Brain ont suggéré que nous définissions le poids de congestion 𝜆 = 0,5 et le poids de densité 𝛾 = 0,5. Les chercheurs ont suivi cette dernière suggestion dans toutes leurs expériences ;
- Nature « place le centre des macros et des groupes de cellules standard au centre des cellules de la grille ». Cependant, CT n'exige pas que les clusters de cellules standard soient placés au centre des cellules de la grille ;
- Nature décrit la génération de la matrice d'adjacence sur la base de la distance de registre entre les paires de nuds. Ceci est cohérent avec la synchronisation qui est une mesure clé de la qualité du placement. Cependant, CT construit la matrice d'adjacence en se basant uniquement sur les connexions directes entre les nuds (c'est-à-dire les macros, les entrées-sorties).
Comment expliquer cette différence ?
On pourrait dire que la création était incomplète, mais il y a peut-être une autre explication. Au fil du temps, l'équipe de l'UCSD a appris que Google avait utilisé un logiciel commercial développé par Synopsys, un important fabricant de suites d'automatisation de la conception électronique (EDA), pour créer un arrangement initial des portes logiques de la puce que le système d'apprentissage par renforcement du géant du web a ensuite optimisé.
Le document de Google mentionne que des outils logiciels standard et des ajustements manuels ont été utilisés après que le modèle a généré un plan, principalement pour s'assurer que le processeur fonctionnerait comme prévu et pour le finaliser en vue de sa fabrication. Les chercheurs de Google ont fait valoir qu'il s'agissait d'une étape nécessaire, que le plan ait été créé par un algorithme d'apprentissage automatique ou par des humains à l'aide d'outils standard, et que leur modèle méritait donc d'être crédité pour l'optimisation du produit final.
Toutefois, l'équipe de l'UCSD a déclaré que l'article de Nature ne mentionnait pas l'utilisation préalable d'outils EDA pour préparer un plan sur lequel le modèle pourrait itérer. Ces outils de Synopsys auraient pu donner au modèle une longueur d'avance suffisante pour remettre en question les capacités réelles du système d'IA.
L'équipe universitaire a écrit à propos de l'utilisation de la suite Synopsys pour préparer un schéma pour le modèle : cela n'était pas apparent lors de l'examen de l'article, et n'est pas mentionné dans Nature. Les expériences montrent que le fait de disposer d'informations sur le placement initial peut améliorer de manière significative les résultats de la tomodensitométrie.
Clarifier les éléments de la "boîte noire" du CT
Voici, expliqué, deux éléments clés de la « boîte noire » du CT : le placement forcé et le calcul des coûts par procuration. Aucun de ces éléments n'est clairement documenté dans Nature, ni visible dans le CT. Ces exemples sont représentatifs de la rétro-ingénierie nécessaire pour comprendre et réimplémenter des méthodes qui, à ce jour, ne sont visibles qu'à travers des API.
Notons que lors de l'exécution du placement dirigé par la force et du calcul du coût du proxy, CT suppose que chaque cluster de cellules standard a une forme carrée. Le placement dirigé par la force (FD) est utilisé pour placer des clusters de cellules standard en fonction des emplacements fixes des macros et des ports IO. Pendant le FD, seuls les clusters de cellules standard peuvent être déplacés et ils ne sont pas nécessairement placés sur les centres de la grille.
Au début de la FD, toutes les grappes de cellules standard sont placées au centre du canevas. Ensuite, les emplacements des clusters de cellules standard sont mises à jour de manière itérative. Chaque itération calcule d'abord les forces exercées sur chaque nud (macro, grappe de cellules standard). Il existe deux types de forces entre les nuds : les forces attractives et les forces répulsives.
La force d'attraction 𝐹𝑎 ne s'applique qu'aux paires de nuds reliés par des réseaux. Tous les réseaux à plusieurs broches sont décomposés en réseaux à deux broches à l'aide du modèle en étoile. Pour le réseau à deux broches reliant la broche 𝑃1 du nud 𝑀1 et 𝑃2 du nud 𝑀2, les composantes de la force d'attraction appliquées à 𝑀1 et 𝑀2 sont 𝐹𝑎𝑥 = 𝑘𝑎 × 𝑎𝑏𝑠[𝑃1.𝑥 - 𝑃2.𝑥] et 𝐹𝑎𝑦 = 𝑘𝑎 × 𝑎𝑏𝑠[𝑃1.𝑦 - 𝑃2.𝑦], où 𝑘𝑎 est le facteur d'attraction. Si l'une des broches est un port IO, 𝑘𝑎 est égal au facteur d'attractivité multiplié par le facteur IO (par défaut = 1,0).
La force de répulsion 𝐹𝑟 ne s'applique qu'aux nuds qui se chevauchent l'un sur l'autre. Les coordonnées du centre de chaque nud 𝑀 sont indiqués en utilisant [𝑀.𝑥, 𝑀.𝑦]. Pour deux nuds 𝑀1 et 𝑀2 qui se chevauchent, les composantes de la force de répulsion appliquées à 𝑀1 et 𝑀2 sont 𝐹𝑟𝑥 =
où 𝑘𝑟 est le facteur répulsif, 𝐹𝑟𝑚𝑎𝑥 est la distance maximale de déplacement et 𝑑𝑖𝑠𝑡(𝑀1, 𝑀2) est la distance euclidienne entre les centres de 𝑀1 et 𝑀2.
Nature enquête sur la recherche de Google
Certains universitaires ont depuis demandé à Nature de revoir l'article de Google à la lumière de l'étude de l'UCSD. Dans des courriels adressés à la revue, des chercheurs auraient souligné les préoccupations soulevées par le professeur Kahng et ses collègues, et se seraient demandé si l'article de Google était trompeur.
Bill Swartz, maître de conférences en génie électrique à l'université du Texas à Dallas, a déclaré que l'article de Nature « laissait beaucoup [de chercheurs] dans l'ignorance », car les résultats concernaient les TPU exclusives du titan de l'internet et étaient donc impossibles à vérifier.
L'utilisation du logiciel de Synopsys pour amorcer le logiciel de Google doit faire l'objet d'une enquête, a-t-il ajouté. « Nous voulons tous connaître l'algorithme réel afin de pouvoir le reproduire. Si les affirmations [de Google] sont justes, nous voulons les mettre en uvre. Il devrait y avoir de la science, tout devrait être objectif ; si ça marche, ça marche », a-t-il déclaré.
Nature a déclaré qu'elle examinait l'article de Google, sans toutefois préciser ce sur quoi elle enquêtait ni pourquoi. « Nous ne pouvons pas commenter les détails des cas individuels pour des raisons de confidentialité », a déclaré un porte-parole de Nature. « Toutefois, d'une manière générale, lorsque des inquiétudes sont soulevées au sujet d'un article publié dans la revue, nous les examinons attentivement en suivant une procédure établie. Ce processus implique une consultation avec les auteurs et, le cas échéant, l'avis de pairs évaluateurs et d'autres experts externes. Lorsque nous disposons de suffisamment d'informations pour prendre une décision, nous donnons la réponse la plus appropriée et la plus claire possible à nos lecteurs ».
Ce n'est pas la première fois que la revue procède à un examen post-publication de l'étude, qui fait l'objet d'un examen minutieux. L'article de Google est resté en ligne avec une correction ajoutée en mars 2022, qui incluait un lien vers une partie du code CT open source de Google pour ceux qui essaient de suivre les méthodes de l'étude.
Pas de pré-entraînement et pas assez de calcul ?
Les auteurs principaux de l'article de Google, Azalia Mirhoseini et Anna Goldie, ont déclaré que le travail de l'équipe de l'UCSD n'est pas une mise en uvre précise de leur méthode. Elles soulignent que le groupe du professeur Kahng a obtenu de moins bons résultats parce qu'il n'a pas entraîné son modèle au préalable sur des données.
« Une méthode basée sur l'apprentissage donnera évidemment de moins bons résultats si elle n'est pas autorisée à apprendre à partir d'expériences antérieures. Dans notre article paru dans Nature, nous effectuons un pré-entraînement sur 20 blocs avant d'évaluer les cas de test retenus », ont déclaré les deux chercheurs dans un communiqué.
L'équipe du professeur Kahng n'a pas non plus entraîné son système en utilisant la même puissance de calcul que celle utilisée par Google, et a suggéré que cette étape n'avait peut-être pas été réalisée correctement, ce qui a nui aux performances du modèle. Mirhoseini et Goldie ont également déclaré que l'étape de prétraitement à l'aide d'applications EDA, qui n'était pas explicitement décrite dans leur article de Nature, n'était pas suffisamment importante pour être mentionnée.
« L'article [de l'UCSD] se concentre sur l'utilisation du placement initial de la synthèse physique pour regrouper les cellules standard, mais cela ne pose aucun problème pratique. La synthèse physique doit être effectuée avant d'exécuter toute méthode de placement », ont-ils déclaré. Il s'agit d'une pratique courante dans la conception des puces.
Le groupe de l'UCSD a toutefois déclaré qu'il n'avait pas procédé à un pré-entraînement de son modèle parce qu'il n'avait pas accès aux données propriétaires de Google. Ils ont toutefois affirmé que leur logiciel avait été vérifié par deux autres ingénieurs de Google, qui figurent également parmi les coauteurs de l'article de Nature. Le professeur Kahng présentera l'étude de son équipe lors de la conférence International Symposium on Physical Design de cette année.
Source : A graph placement methodology for fast chip design
Et vous ?
Quel est votre avis sur le sujet ?
Voir aussi :

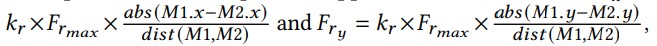
 Répondre avec citation
Répondre avec citation
Partager