













Un robot bipède capable de jouer au football avec agilité grâce à l'apprentissage par renforcement profond,
une présentation des chercheurs de DeepMind
Les chercheurs de DeepMind présentent une méthode dapprentissage par renforcement profond pour enseigner à un robot bipède des compétences de football agiles, telles que le dribble, le tir et le contrôle du ballon. Les auteurs utilisent une simulation réaliste basée sur la physique et un robot NAO comme plateforme expérimentale. Ils proposent une architecture modulaire qui combine des politiques locales spécialisées et une politique globale hiérarchique. Ils montrent que leur méthode permet au robot dapprendre des comportements complexes et robustes face à des situations variées et imprévisibles. Ils évaluent leur approche sur des tâches de football individuelles et collectives, et comparent leurs résultats avec des méthodes de létat de lart.
La création d'une intelligence corporelle générale, c'est-à-dire la création d'agents capables d'agir dans le monde physique avec agilité, dextérité et compréhension - comme le font les animaux ou les humains - est l'un des objectifs de longue date des chercheurs en IA et des roboticiens. Les animaux et les humains ne sont pas seulement maîtres de leur corps, capables d'exécuter et de combiner des mouvements complexes de manière cohérente et sans effort, mais ils perçoivent et comprennent également leur environnement et utilisent leur corps pour obtenir des résultats complexes dans le monde.
Ces dernières années, la logique profonde a été de plus en plus appliquée aux robots physiques. En particulier, les robots quadrupèdes à jambes de haute qualité sont devenus largement disponibles et ont été la cible d'un certain nombre de démonstrations de la façon dont l'apprentissage peut générer une large gamme de comportements de locomotion robustes. Le mouvement dans des environnements statiques ne représente qu'un sous-ensemble des nombreuses façons dont les animaux et les humains peuvent déployer leur corps pour interagir avec le monde.
Les exemples incluent l'escalade, les compétences de football comme le dribble ou la capture, et l'utilisation des jambes pour une manipulation simple. Alors que de nombreux travaux se sont concentrés sur les quadrupèdes, qui sont intrinsèquement stables, un petit nombre de travaux ont abordé la locomotion et d'autres mouvements pour les bipèdes et les humanoïdes, qui posent des défis supplémentaires, en particulier en ce qui concerne la stabilité et la sécurité.
Ces exemples sont encourageants, mais la création de comportements multi-compétences sophistiqués à long terme qui peuvent être composés, s'adapter à des contextes environnementaux différents et être exécutés en toute sécurité sur des robots réels reste un problème difficile en raison des difficultés de spécification des récompenses et de la nécessité d'équilibrer des objectifs conflictés pour obtenir des mouvements non seulement dynamiques et agiles, mais aussi sûrs.
Les sports comme le football mettent en évidence de nombreuses caractéristiques de l'intelligence sensorimotrice humaine. Dans toute sa complexité, le football exige un ensemble varié de mouvements très agiles et dynamiques, notamment courir, tourner, faire un pas de côté, donner un coup de pied, faire une passe, rattraper une chute, interagir avec un objet, et bien d'autres encore, qui doivent être composés de diverses manières. Les joueurs doivent en outre être capables de faire des prévisions concernant le ballon, leurs coéquipiers et leurs adversaires, et d'adapter leurs mouvements au contexte du jeu.
Les joueurs doivent également coordonner leurs mouvements sur de longues périodes afin de parvenir à un jeu tactique et coordonné. Cette diversité de défis a été reconnue par les communautés de la robotique et de l'intelligence artificielle, notamment dans le cadre de la compétition RoboCup. Les comportements agiles, flexibles et réactifs - et les transitions fluides entre eux - nécessaires pour bien jouer au football sont difficiles et longs à concevoir manuellement pour un robot.
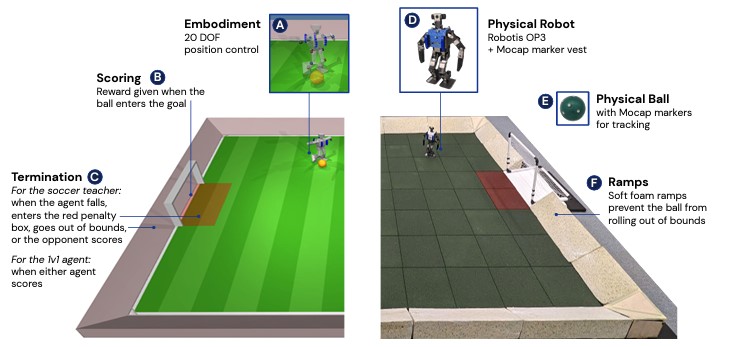
Les chercheurs ont créé des environnements de football simulés (à gauche) et réels (à droite). Le terrain est long de 5 ml et large de 4 m. L'environnement réel était aussi équipé d'un système de capture de mouvement (mocap) pour suivre les deux robots et le ballon.
Lobjectif des chercheurs est d'entraîner un agent qui compose le large éventail de compétences requises pour le football - y compris marcher, botter, se relever du sol, marquer et défendre - en un comportement stratégique à long terme, que nous pouvons ensuite transférer à un vrai robot. Ces comportements n'apparaissent pas si l'on se contente d'entraîner les agents sur la base d'une récompense éparse pour avoir marqué des buts, en raison de deux difficultés principales : l'exploration et l'apprentissage de comportements transférables.
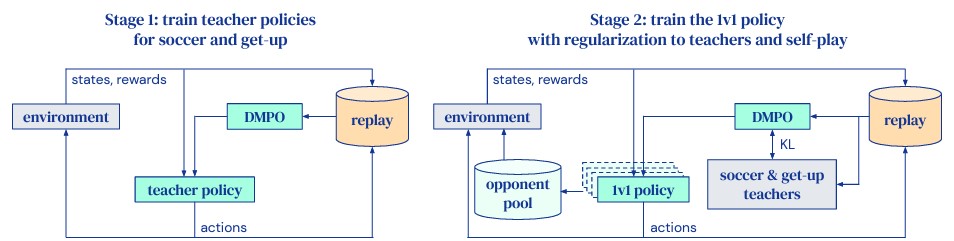
Ces difficultés sont surmontées en divisant l'entraînement en deux étapes, comme le montre la figure ci-dessous. Dans la première étape, les chercheurs entraînent les politiques de l'enseignant pour deux compétences spécifiques : se lever du sol et marquer des points contre un adversaire non entraîné. Lors de l'apprentissage de cette dernière compétence, l'épisode se termine lorsque l'agent est au sol. Sans cette terminaison, les agents trouvent un minimum local et apprennent à rouler sur le sol en direction du ballon pour le frapper dans le but, plutôt que de marcher et de frapper du pied.
Dans la deuxième étape, les politiques de l'enseignant de la première étape sont utilisées pour régulariser l'agent, tandis qu'il apprend à jouer effectivement contre des adversaires de plus en plus forts. Cette dernière étape permet à l'agent d'apprendre des tactiques et des stratégies telles que la défense et l'anticipation des mouvements de l'adversaire. Les chercheurs utilisent une forme d'auto-jeu, où les adversaires sont échantillonnés à partir des versions précédentes de l'agent entraîné.
Il s'agit d'une forme d'apprentissage automatique : la force des adversaires augmente au fur et à mesure que l'agent s'améliore, ce qui l'incite à s'améliorer davantage. Pour faciliter le transfert, la randomisation du domaine, les perturbations aléatoires, le bruit des capteurs et les retards sont incorporés dans la formation en simulation.
Apprentissage des robots
Les chercheurs ont formé des agents de football en deux étapes. Dans la première étape (à gauche), ils forment un professeur de football et un professeur de lever séparés. Au cours de la deuxième étape (à droite), ils distillent ces deux enseignants en un seul agent capable de se lever du sol et de jouer au football. La deuxième étape incorpore également l'auto-jeu : l'adversaire est uniformément échantillonné au hasard à partir d'un pool composé d'instantanés de politique obtenus plus tôt au cours de la formation. Ils disent avoir constaté que cette approche en deux étapes conduit à un comportement qualitativement meilleur et à un meilleur transfert de la simulation à la réalité, par rapport à la formation d'un agent à partir de zéro.
Les robots à jambes ont connu un regain d'intérêt pour la recherche ces dernières années. Cet intérêt a été alimenté de manière inégale par la prolifération de plateformes matérielles adaptées à la recherche et par la prise de conscience que les comportements de locomotion peuvent être créés de manière effective par des techniques de deep RL. Bien qu'il y ait eu quelques tentatives pour entraîner des robots à jambes à marcher avec la deep RL directement sur le matériel. La grande majorité des travaux s'appuient sur une forme de transfert de la simulation à la réalité, contournant ainsi bon nombre des préoccupations en matière de sécurité et d'efficacité des données associées à la formation directement sur le matériel.
Un thème commun est qu'un nombre étonnamment faible de techniques peut être sufficient pour réduire l'écart entre la simulation et la réalité, en partie grâce à la qualité relativement élevée du matériel moderne pour les jambes. Des travaux récents ont démontré la capacité à traverser une variété de terrains complexes,sans fil et purement guidés par la perception embarquée.
Tant la disponibilité immédiate des plateformes quadrupèdes que leur stabilité et leur sécurité relatives par rapport aux bipèdes en ont fait la cible principale de la recherche sur les mouvements. Cependant, le matériel bipède s'est également amélioré, et des travaux récents ont produit des comportements tels que la marche et la course, la montée d'escaliers, et le saut. Bien que très robustes, ces comportements sont relativement conservateurs, probablement pour des raisons de sécurité.
La plupart des travaux récents se sont concentrés sur des bipèdes et des humanoïdes de grande qualité et de taille normale, un nombre beaucoup plus restreint ciblant des plateformes plus basiques dont les actionneurs et les capteurs plus simples et moins précis posent des défis supplémentaires en termes de transfert simulé-réel. Le travail des chercheurs constitue un pas en avant vers l'utilisation pratique de la RL profonde pour le contrôle agile des robots humanoïdes dans un cadre dynamique multi-agents. Cependant, il y a plusieurs limitations que ce travail ne couvre pas, ou qu'il n'aborde que superficiellement.We just released our work on robot soccer. I've been working on this for quite some time with my amazing colleagues at DeepMind. It's exciting how deep RL can produce such beautiful behaviors with low-cost robots. Full paper is available at https://t.co/A65rPLL7UD Enjoy! pic.twitter.com/n8j4uELhIL
— Tuomas Haarnoja (@haarnoja) April 27, 2023
Premièrement, les comportements de bas niveau sont nécessairement un compromis entre la stabilité et le dynamisme ; les chercheurs pourraient potentiellement obtenir des comportements qui améliorent ces deux aspects en utilisant les connaissances de la RL multi-objectifs. Deuxièmement, les chercheurs n'exploitent pas de données réelles pour le transfert ; au lieu de cela, leur approche repose uniquement sur le transfert de simulateur.
Troisièmement, ils ont choisi des actions basées sur la position en raison de la simplicité et de l'effet stabilisateur d'un contrôleur de position rapide, mais ils indiquent que d'autres modes de contrôle, tels que le contrôle par courant continu ou le contrôle dynamique des paramètres de rétroaction, pourraient conduire à un comportement plus humain et améliorer le rejet des perturbations et la sécurité. Quatrièmement, ils ont appliqué leur méthode à un petit robot et n'ont pas pris en compte les défis supplémentaires qui seraient associés à un facteur de forme plus important.
Source : Tweet de Tuomas Haarnoja
Et vous ?
La méthode dapprentissage par renforcement profond présentée par les chercheurs de DeepMind est-elle pertinente ?
Voir aussi :

 Répondre avec citation
Répondre avec citation







Partager