













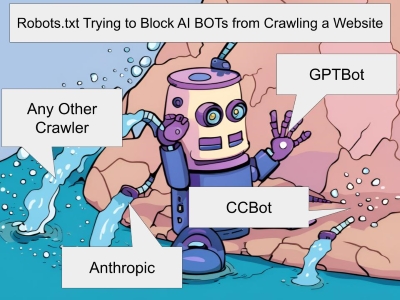
OpenAI dévoile GPTBot, un bot qui explore les données du Web public pour l'apprentissage de l'IA, pour répondre aux plaintes concernant l'utilisation de données de sites Web.
OpenAI a lancé un nouveau web crawler appelé GPTBot pour collecter les données publiques disponibles sur Internet afin d'entraîner les modèles d'intelligence artificielle. Ce lancement intervient dans un contexte de controverses récentes où des entreprises technologiques ont été accusées de récupérer des sites web sans consentement explicite pour alimenter de grands modèles de langage tels que GPT-4.
GPTBot se veut plus transparent, en s'identifiant correctement pour permettre aux webmasters d'autoriser ou non l'accès. Le robot utilise le jeton d'agent utilisateur "GPTBot" et une chaîne d'agent utilisateur complète indiquant clairement qu'il provient d'OpenAI.
OpenAI précise que GPTBot n'accède qu'aux sites qui ne requièrent pas d'inscription à un paywall, qui ne recueillent pas de données d'utilisateur personnellement identifiables ou qui ne contiennent pas de texte violant la politique de l'entreprise. L'entreprise affirme que l'autorisation du bot peut contribuer à améliorer la précision et les capacités des systèmes d'intelligence artificielle.
Code : Sélectionner tout - Visualiser dans une fenêtre à part
2
Ce lancement reflète la réponse d'OpenAI aux récentes critiques concernant les grands modèles de langage tels que GPT-4 qui ont été formés sur des données de sites web sans autorisation explicite. Même si le contenu est accessible au public, les critiques soutiennent qu'il devrait toujours y avoir des accords d'acceptation pour l'entraînement de l'IA. Ils s'inquiètent également du fait que le contenu soit sorti de son contexte lorsqu'il est introduit dans les systèmes d'intelligence artificielle.
Le lancement de GPTBot met en évidence les zones d'ombre entourant l'utilisation de données accessibles au public pour développer des modèles d'IA, qui peuvent bénéficier de vastes ensembles de données d'entraînement. Il illustre les débats éthiques qui émergent au fur et à mesure que les capacités de l'IA progressent. À l'avenir, des lignes directrices plus claires en matière de protection de la vie privée et des cadres éthiques seront nécessaires pour trouver le bon équilibre.
Voici quelques informations publiées par OpenAI sur l'utilisation de GPTBot :
Source : OpenAIUtilisation
Les pages web explorées avec l'agent utilisateur GPTBot peuvent potentiellement être utilisées pour améliorer les modèles futurs et sont filtrées pour supprimer les sources qui nécessitent un accès payant, qui sont connues pour collecter des informations personnelles identifiables (PII), ou qui contiennent du texte qui viole nos politiques. Permettre à GPTBot d'accéder à votre site peut aider les modèles d'IA à devenir plus précis et à améliorer leurs capacités générales et leur sécurité. Nous vous expliquons ci-dessous comment empêcher GPTBot d'accéder à votre site.
Désactiver GPTBot
Pour empêcher GPTBot d'accéder à votre site, vous pouvez ajouter GPTBot au fichier robots.txt de votre site :
Personnaliser l'accès à GPTBot
Code : Sélectionner tout - Visualiser dans une fenêtre à part
2
Pour permettre à GPTBot d'accéder uniquement à certaines parties de votre site, vous pouvez ajouter le jeton GPTBot au fichier robots.txt de votre site comme suit :
Code : Sélectionner tout - Visualiser dans une fenêtre à part
2
3
Et vous ?
Pensez-vous que cette annonce est crédible ou pertinente ?
Voir aussi :
« Nous ne le faisons pas et ne le ferons pas avant un certain temps »
Des données d'enfants, d'artistes et d'écrivains prises sans consentement

 Répondre avec citation
Répondre avec citation










Partager