













Meta et Microsoft annoncent qu'ils achèteront la nouvelle puce d'IA d'AMD pour remplacer celle de Nvidia
Microsoft et Meta utiliseront la nouvelle puce AMD comme alternative à Nvidia. AMD a terminé en légère baisse mercredi, même après que Meta et Microsoft aient déclaré qu'ils utiliseraient sa dernière puce d'intelligence artificielle comme alternative à Nvidia.
Le MI300X est-il comparable au H100 de Nvidia ?
Instinct MI300X - un nouvel accélérateur qui, selon AMD, commencera à être livré dans les mois à venir, devrait coûter moins cher que les produits concurrents de Nvidia, dont le prix peut atteindre 40 000 dollars.
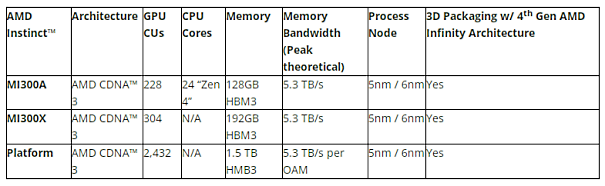
Lisa Su, directrice générale d'Advanced Micro Devices, a même comparé cette puce, qui offre 192 Go de mémoire HBM3, directement avec le Nvidia H100 lors d'un événement organisé à l'intention des investisseurs.
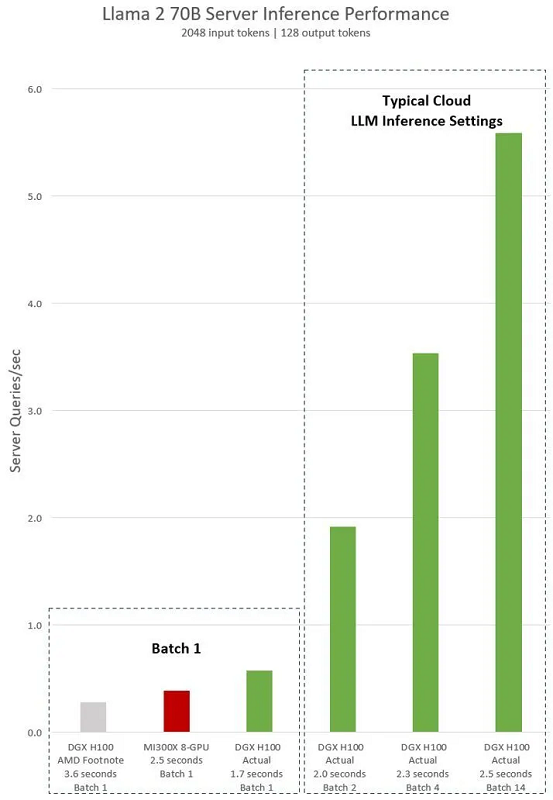
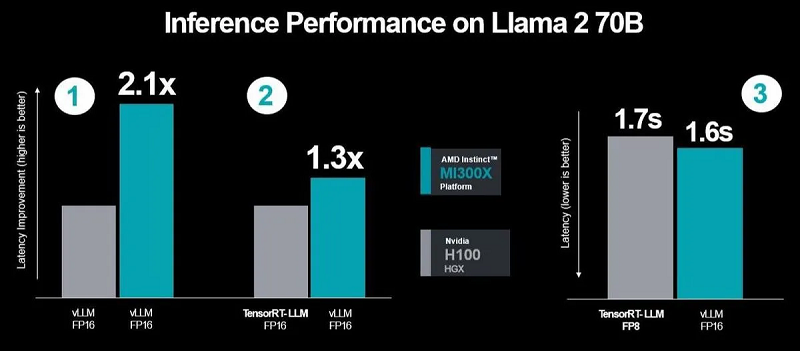
L'action AMD est actuellement en hausse de plus de 80 % sur l'année.Ces performances se traduisent directement par une meilleure expérience utilisateur. Lorsque vous demandez quelque chose à un modèle, vous aimeriez qu'il vous réponde plus rapidement, surtout lorsque les réponses sont de plus en plus complexes.
La nouvelle puce AMD pourrait nuire aux ventes de Nvidia
Si l'Instinct MI300X est effectivement bien accueilli par les grands noms de la technologie qui travaillent sur des applications d'IA, il constituera une concurrence significative pour Nvidia et pourrait réduire ses ventes, qui ont plus que triplé au cours du troisième trimestre.
Il est à noter que Nvidia a déjà mis en garde contre un impact sur son trimestre actuel en raison des restrictions américaines sur l'exportation de puces sophistiquées vers la Chine.
Mercredi, Lisa Su a annoncé aux investisseurs qu'AMD avait également amélioré sa suite logicielle (ROCm), supprimant ainsi une autre lacune qui incitait les développeurs d'intelligence artificielle à préférer les produits Nvidia.
Wall Street accorde actuellement une note consensuelle d'"achat" aux actions du géant californien des semi-conducteurs.
Source : AMD
Et vous ?
Quel est votre avis sur le sujet ?
Voir aussi :
 Répondre avec citation
Répondre avec citation










Partager