











Google DeepMind a utilisé un grand modèle de langage pour résoudre un problème mathématique insoluble, "c'est une façon intéressante d'exploiter la puissance des LLM", déclare Terence Tao.
Google DeepMind a utilisé un grand modèle de langage pour résoudre un célèbre problème non résolu en mathématiques pures. Dans un article publié aujourd'hui dans Nature, les chercheurs affirment que c'est la première fois qu'un grand modèle de langage est utilisé pour découvrir la solution d'une énigme scientifique de longue date, produisant ainsi de nouvelles informations vérifiables et précieuses qui n'existaient pas auparavant. "Cette information ne figurait pas dans les données d'entraînement, elle n'était même pas connue", explique Pushmeet Kohli, coauteur de l'étude et vice-président de la recherche chez Google DeepMind.
Les grands modèles de langage ont la réputation d'inventer des choses, et non de fournir de nouveaux faits. Le nouvel outil de Google DeepMind, appelé FunSearch, pourrait changer la donne. Il montre qu'ils peuvent en effet faire des découvertes, à condition d'y être incités et de rejeter la majorité de leurs résultats. FunSearch (appelé ainsi parce qu'il recherche des fonctions mathématiques, et non parce qu'il est amusant) s'inscrit dans la lignée des découvertes en mathématiques fondamentales et en informatique que DeepMind a réalisées grâce à l'IA. AlphaTensor a d'abord trouvé un moyen d'accélérer un calcul au cur de nombreux types de code, battant ainsi un record vieux de 50 ans. Ensuite, AlphaDev a trouvé des moyens d'accélérer l'exécution d'algorithmes clés utilisés des milliers de fois par jour.
Pourtant, ces outils n'utilisaient pas de grands modèles de langage. Construits au-dessus d'AlphaZero, l'IA joueuse de DeepMind, ils ont tous deux résolu des problèmes mathématiques en les traitant comme s'il s'agissait de casse-tête au jeu de Go ou d'échecs. Le problème, c'est qu'ils sont coincés dans leur voie, explique Bernardino Romera-Paredes, un chercheur de l'entreprise qui a travaillé à la fois sur AlphaTensor et FunSearch : "AlphaTensor est excellent pour la multiplication matricielle, mais il ne fait pratiquement rien d'autre."
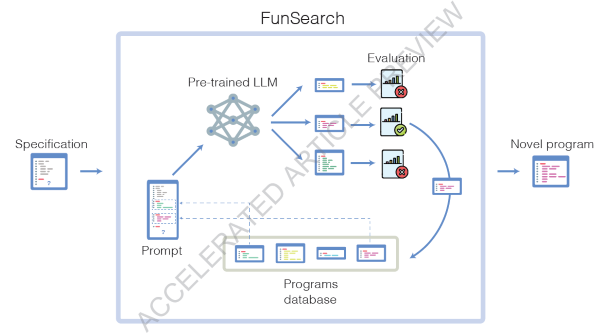
FunSearch adopte une approche différente. Il combine un grand modèle de langage appelé Codey, une version du PaLM 2 de Google qui est affinée sur le code informatique, avec d'autres systèmes qui rejettent les réponses incorrectes ou absurdes et y réintègrent les bonnes. "Pour être très honnête avec vous, nous avons des hypothèses, mais nous ne savons pas exactement pourquoi cela fonctionne", déclare Alhussein Fawzi, chercheur chez Google DeepMind. "Au début du projet, nous ne savions pas du tout si cela fonctionnerait."
Les chercheurs ont commencé par esquisser le problème qu'ils voulaient résoudre en Python, un langage de programmation très répandu. Mais ils ont omis les lignes du programme qui spécifieraient la manière de le résoudre. C'est là que FunSearch entre en jeu. Il demande à Codey de remplir les blancs, c'est-à-dire de suggérer un code qui résoudra le problème. Un deuxième algorithme vérifie et note les propositions de Codey. Les meilleures suggestions, même si elles ne sont pas encore correctes, sont sauvegardées et remises à Codey, qui essaie à nouveau de compléter le programme. "De nombreuses suggestions seront absurdes, d'autres seront sensées et quelques-unes seront vraiment inspirées", explique M. Kohli. Vous prenez celles qui sont vraiment inspirées et vous dites : "D'accord, prenez celles-là et répétez".
Après quelques millions de suggestions et quelques dizaines de répétitions du processus global (ce qui a pris quelques jours), FunSearch a réussi à trouver un code qui produisait une solution correcte et inconnue jusqu'alors au problème de l'ensemble de tête, qui consiste à trouver la plus grande taille d'un certain type d'ensemble. Imaginez que vous tracez des points sur du papier millimétré. Le problème de l'ensemble maximal revient à essayer de déterminer le nombre de points que l'on peut placer sans que trois d'entre eux ne forment jamais une ligne droite.
C'est un sujet très pointu, mais important. Les mathématiciens ne sont même pas d'accord sur la manière de le résoudre, et encore moins sur la solution. (Elle est également liée à la multiplication des matrices, le calcul qu'AlphaTensor a trouvé le moyen d'accélérer). Terence Tao, de l'université de Californie à Los Angeles, qui a remporté plusieurs des plus grands prix de mathématiques, dont la médaille Fields, a qualifié le problème de l'ensemble des casquettes de "peut-être ma question ouverte préférée" dans un billet de blog datant de 2007. Tao est intrigué par les possibilités offertes par FunSearch. "Il s'agit d'un paradigme prometteur", déclare-t-il. "C'est une façon intéressante d'exploiter la puissance des grands modèles de langage.
L'un des principaux avantages de FunSearch par rapport à AlphaTensor est qu'il peut, en théorie, être utilisé pour trouver des solutions à un large éventail de problèmes. En effet, il produit du code - une recette pour générer la solution - plutôt que la solution elle-même. Un code différent résoudra des problèmes différents. Les résultats de FunSearch sont également plus faciles à comprendre. Une recette est souvent plus claire que la solution mathématique bizarre qu'elle produit, explique M. Fawzi.
Pour tester la polyvalence de FunSearch, les chercheurs l'ont utilisé pour résoudre un autre problème mathématique difficile : le problème de l'emballage d'objets dans des bacs, qui consiste à essayer d'emballer des objets dans le moins de bacs possible. Ce problème est important pour toute une série d'applications en informatique, de la gestion des centres de données au commerce électronique. FunSearch a trouvé un moyen de le résoudre plus rapidement que les méthodes conçues par l'homme.
Les mathématiciens "essaient encore de trouver le meilleur moyen d'incorporer de grands modèles de langage dans notre processus de recherche de manière à exploiter leur puissance tout en atténuant leurs inconvénients", déclare Tao. "Ce projet indique certainement une voie possible à suivre.
Source : Mathematical discoveries from program search with large language modelsRésumé
Les grands modèles de langage (LLM) ont démontré d'énormes capacités à résoudre des tâches complexes, du raisonnement quantitatif à la compréhension du langage naturel. Cependant, les LLM souffrent parfois de confabulations (ou d'hallucinations) qui peuvent les amener à faire des déclarations plausibles mais incorrectes. Cela entrave l'utilisation des grands modèles actuels dans la découverte scientifique. Nous présentons ici FunSearch (abréviation de searching in the function space), une procédure évolutive basée sur l'association d'un LLM pré-entraîné avec un évaluateur systématique. Nous démontrons l'efficacité de cette approche pour surpasser les meilleurs résultats connus dans des problèmes importants, en repoussant les limites des approches existantes basées sur le LLM. En appliquant FunSearch à un problème central de la combinatoire extrémale - le problème de l'ensemble plafond - nous découvrons de nouvelles constructions de grands ensembles plafonds dépassant les meilleurs résultats connus, à la fois en dimension finie et dans les cas asymptotiques.
Il s'agit des premières découvertes faites pour des problèmes ouverts établis à l'aide de LLM. Nous démontrons la généralité de FunSearch en l'appliquant à un problème algorithmique, le bin packing en ligne, en trouvant de nouvelles heuristiques qui améliorent les lignes de base largement utilisées. Contrairement à la plupart des approches de recherche informatique, FunSearch recherche des programmes qui décrivent comment résoudre un problème, plutôt que la solution. En plus d'être une stratégie efficace et évolutive, les programmes découverts ont tendance à être plus interprétables que les solutions brutes, ce qui permet des boucles de rétroaction entre les experts du domaine et FunSearch, ainsi que le déploiement de ces programmes dans des applications réelles.
Discussion
L'efficacité de FunSearch dans la découverte de nouvelles connaissances pour des problèmes difficiles peut sembler intrigante. Nous pensons que le LLM utilisé dans FunSearch n'utilise pas beaucoup de contexte sur le problème ; le LLM devrait plutôt être considéré comme une source de programmes divers (syntaxiquement corrects) avec des idées occasionnellement intéressantes. Lorsqu'il est contraint d'opérer sur la partie cruciale de l'algorithme avec un squelette de programme, le LLM fournit des suggestions qui améliorent marginalement celles qui existent dans la population, ce qui aboutit finalement à la découverte de nouvelles connaissances sur des problèmes ouverts lorsqu'il est combiné avec l'algorithme évolutionnaire. Un autre élément crucial de l'efficacité de FunSearch est qu'il opère dans l'espace des programmes : plutôt que de rechercher directement des constructions (ce qui est typiquement une énorme liste de nombres), FunSearch recherche des programmes générant ces constructions. Comme la plupart des problèmes qui nous intéressent sont structurés (hautement non aléatoires), nous supposons que les solutions sont décrites de manière plus concise avec un programme informatique qu'avec d'autres représentations. Par exemple, la représentation triviale de l'ensemble admissible A consiste en plus de 200 000 vecteurs, mais le programme générant cet ensemble ne consiste qu'en quelques lignes de code. Comme FunSearch encourage implicitement les programmes concis, il s'adapte à des instances beaucoup plus grandes que les approches de recherche traditionnelles pour les problèmes structurés.
Dans un sens large, FunSearch tente de trouver des solutions qui ont une faible complexité de Kolmogorov (qui est la longueur du programme informatique le plus court qui produit un objet donné en sortie), alors que les procédures de recherche traditionnelles ont un biais inductif très différent. Nous pensons qu'un tel biais inductif comprimé par Kolmogorov est essentiel pour que FunSearch puisse s'adapter aux grandes instances de nos cas d'utilisation. En plus de l'échelle, nous avons empiriquement observé que FunSearch produit des programmes qui ont tendance à être interprétables - c'est-à-dire qu'ils sont clairement plus faciles à lire et à comprendre qu'une liste de nombres. Par exemple, en examinant attentivement les résultats de FunSearch pour le problème des ensembles admissibles, nous avons trouvé une nouvelle symétrie, qui a ensuite été utilisée pour améliorer encore les résultats. Malgré la rareté des solutions symétriques, nous observons que FunSearch a préféré les solutions symétriques, car elles sont plus parcimonieuses (c'est-à-dire qu'elles nécessitent moins d'informations à spécifier), en plus du biais naturel des LLM (formés sur du code produit par l'homme) dans la production de code avec des caractéristiques similaires au code humain. Cela contraste avec la programmation génétique traditionnelle qui n'a pas ce biais (et qui nécessite en outre un réglage manuel des opérateurs de mutation).
Nous notons que FunSearch fonctionne actuellement mieux pour les problèmes présentant les caractéristiques suivantes : a) disponibilité d'un évaluateur efficace ; b) un retour de notation "riche" quantifiant les améliorations (par opposition à un signal binaire) ; c) capacité à fournir un squelette avec une partie isolée à faire évoluer. Par exemple, le problème de la génération de preuves pour les théorèmes sort de ce cadre, car il n'est pas clair comment fournir un signal de notation suffisamment riche. En revanche, pour MAX-SAT, le nombre de clauses satisfaites peut être utilisé comme signal de notation. Dans le présent document, nous nous sommes explicitement efforcés d'être simples et nous sommes convaincus que FunSearch peut être étendu afin d'améliorer ses performances et d'être applicable à d'autres classes de problèmes. En outre, le développement rapide des LLM est susceptible d'aboutir à des échantillons de qualité bien supérieure à une fraction du coût, ce qui rendra FunSearch plus efficace pour traiter un large éventail de problèmes. En conséquence, nous pensons que les algorithmes adaptés automatiquement deviendront bientôt une pratique courante et seront déployés dans des applications réelles.
Et vous ?
Pensez-vous que cette recherche est crédible ou pertinente ?
Voir aussi :
 Répondre avec citation
Répondre avec citation
Partager