
















La version 1.10 de Julia est disponible, avec de nouvelles fonctionnalités, dont des améliorations de performance et des changements de comportement marginaux et non perturbateurs
Après 3 bêtas et 3 release candidates, la version 1.10 de Julia est enfin disponible. L'équipe de Julia tient à remercier tous les contributeurs de cette version et tous les testeurs qui ont aidé à trouver les régressions et les problèmes dans les pré-versions. Sans eux, cette version n'aurait pas été possible.
La liste complète des changements peut être retrouvée dans la note de version, mais un aperçu plus approfondi de certains des points forts de la version est présenté ici.
Nouvel analyseur syntaxique écrit en Julia
Avec la sortie de Julia 1.10, l'analyseur par défaut, précédemment écrit en Scheme, a été remplacé par un nouvel analyseur, écrit en Julia, connu sous le nom de JuliaSyntax.jl. Ce changement apporte plusieurs améliorations :
- Amélioration de la performance de l'analyseur : Le nouvel analyseur syntaxique est nettement plus performant pour l'analyse du code.
- Messages d'erreur détaillés sur la syntaxe : Les messages d'erreur fournissent désormais des informations plus spécifiques, permettant de localiser avec précision les problèmes de syntaxe.
- Cartographie avancée du code source : L'analyseur génère des expressions qui suivent leur position dans le code source, ce qui facilite la localisation précise des erreurs et permet de construire des outils tels que des linters.
Voici un exemple pour illustrer l'amélioration du message d'erreur :
Message d'erreur Pre Julia 1.10 :
Code : Sélectionner tout - Visualiser dans une fenêtre à part
2
Dans cette version, le message d'erreur est général et ne précise pas l'emplacement de l'erreur de syntaxe.
Message d'erreur de Julia 1.10 :
Code : Sélectionner tout - Visualiser dans une fenêtre à part
2
3
4
5
Ici, le message d'erreur comprend une indication de l'emplacement exact du problème dans le code.
Amélioration du temps de chargement des paquets
Dans la version 1.9, le TTFX (Time To First X, le temps nécessaire pour que le résultat soit disponible la première fois qu'une fonction est appelée) a été fortement amélioré en permettant aux auteurs de paquets d'activer la sauvegarde du code natif pendant la précompilation. Dans la version 1.10, un travail important a été réalisé pour améliorer les performances du chargement des paquets.
Une grande partie de ce travail a consisté à profiler et à améliorer le temps de chargement d'OmniPackage.jl, qui est un "mégapackage" artificiel dont le seul but est de dépendre d'un grand nombre de dépendances et de les charger. Au total, OmniPackage.jl charge environ 650 paquets, dont beaucoup ont une taille importante.
Parmi beaucoup d'autres choses
- Amélioration du système de types qui lui permet de mieux s'adapter à l'augmentation du nombre de méthodes et de types.
- Réduction des invalidations qui déclenchent une recompilation inutile.
- Déplacement des paquets de Requires.jl vers les extensions de paquets (qui peuvent être précompilées).
- Optimisation des mécanismes de distribution mul!
- Nombreuses autres améliorations des performances.
L'exécution de @time à l'aide d'OmniPackage (après précompilation) donne les résultats suivants sur 1.9 et 1.10 respectivement (mesures effectuées sur un Macbook Pro M1) :
Code : Sélectionner tout - Visualiser dans une fenêtre à part
2
3
4
5
Il s'agit donc d'une amélioration de plus de 2 fois la charge d'un très gros paquet. Les paquets individuels peuvent présenter des améliorations plus ou moins importantes.
Amélioration du rendu de la trace de pile
Lorsqu'une erreur survient, Julia imprime l'erreur ainsi qu'un "stacktrace" destiné à aider au débogage de la façon dont l'erreur s'est produite. Ces traces de pile dans Julia sont assez détaillées, contenant des informations comme le nom de la méthode, les noms et types d'arguments, et l'emplacement de la méthode dans le module et le fichier. Cependant, dans des scénarios complexes impliquant des types paramétriques complexes, un seul cadre de trace de pile peut occuper tout l'écran du terminal. Avec la version 1.10 de Julia, des améliorations ont été introduites pour rendre les traces de pile moins verbeuses.
L'un des principaux facteurs contribuant à la longueur des traces de pile est l'utilisation de types paramétriques, en particulier lorsque ces types sont imbriqués les uns dans les autres. Cette complexité peut rapidement s'accroître. Pour y remédier, dans la pull request #49795, le REPL abrège désormais les paramètres avec {...} lorsqu'ils seront excessivement longs. Les utilisateurs peuvent voir la trace complète de la pile en utilisant la commande show sur la variable err définie automatiquement dans le REPL.
Les autres améliorations notables sont les suivantes :
Omettre le nom de la variable #unused# dans les traces de pile. Par exemple, zero(#unused#::Type{Any}) apparaît maintenant comme zero(::Type{Any}).
Simplification de l'affichage des arguments des mots-clés dans les appels de fonction. Par exemple, f( ; x=3, y=2) s'affichait auparavant comme f( ; kw::Base.Pairs{Symbol, Int64, Tuple{Symbol, Symbol}, NamedTuple{(:x, :y), Tuple{Int64, Int64}}) dans une trace de pile. Maintenant, il est affiché comme f( ; kw::@Kwargs{x::Int64, y::Int64}), avec @Kwargs étendu à l'ancien format.
Réduction d'images successives au même endroit. La définition de f(x, y=1) définit implicitement deux méthodes : f(x) (appelant f(x, 1)) et f(x, y). La méthode pour f(x) est maintenant omise dans la trace de pile car elle n'existe que pour appeler f(x, y).
Masquage des méthodes générées en interne, souvent créées pour la transmission d'arguments et portant des noms obscurs comme #f#16.
Pour illustrer cela, considérons le code Julia suivant :
Code : Sélectionner tout - Visualiser dans une fenêtre à part
2
3
Auparavant, la trace de pile de ce code apparaissait comme suit :
Code : Sélectionner tout - Visualiser dans une fenêtre à part
2
3
4
5
6
7
8
9
10
11
12
13Stacktrace: [1] error() @ Base ./error.jl:44 [2] f(g::Function, a::Int64; kw::Base.Pairs{Symbol, Union{}, Tuple{}, NamedTuple{(), Tuple{}}}) @ Main ./REPL[1]:1 [3] f(g::Function, a::Int64) @ Main ./REPL[1]:1 [4] #f#16 @ ./REPL[2]:1 [inlined] [5] f(a::Int64) @ Main ./REPL[2]:1 [6] top-level scope @ REPL[6]:1
Avec les améliorations de Julia 1.10, la trace de pile est maintenant plus concise :
Code : Sélectionner tout - Visualiser dans une fenêtre à part
2
3
4
5
6
7
8
9Stacktrace: [1] error() @ Base ./error.jl:44 [2] f(g::Function, a::Int64; kw::@Kwargs{}) @ Main ./REPL[1]:1 [3] f(a::Int64) @ Main ./REPL[2]:1 [4] top-level scope @ REPL[3]:1
Cette mise à jour permet d'obtenir des traces de piles plus courtes et plus faciles à lire.
Parallélisation du Garbage collection
Dans la version 1.10, la phase de marquage du garbage collector (GC) a été parallélisée et la possibilité d'exécuter une partie de la phase de balayage en même temps que les threads de l'application a été introduite. Cela se traduit par des accélérations significatives du temps de GC pour les charges de travail multithreads à forte allocation.
Le GC multithread peut être activé grâce à l'option de ligne de commande --gcthreads=M, qui spécifie le nombre de threads à utiliser dans la phase de marquage du GC. Il est également possible d'activer le balayage simultané des pages mentionné ci-dessus avec l'option --gcthreads=M,1, ce qui signifie que M threads seront utilisés dans la phase de marquage du GC et qu'un thread GC sera responsable de l'exécution d'une partie de la phase de balayage en même temps que l'application.
Le nombre de threads GC est fixé par défaut à la moitié du nombre de threads de calcul (--threads).
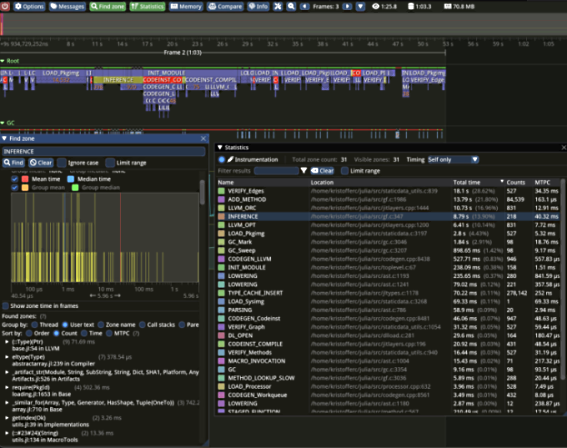
Intégration du profilage ITTAPI de Tracy et Intel VTune
Le runtime Julia a gagné des capacités d'intégration supplémentaires avec le profiler Tracy ainsi que le profiler VTune d'Intel. Les profileurs sont maintenant capables de rapporter des événements notables tels que la compilation, les GC majeurs et mineurs, l'invalidation et les compteurs de mémoire, et plus encore. Le support du profilage peut être activé lors de la compilation de Julia via les options make WITH_TRACY=1 et WITH_ITTAPI=1. L'objectif est de rendre ces profileurs utilisables sans avoir à reconstruire Julia dans les versions futures de Julia.
Vous trouverez ci-dessous un exemple d'utilisation de Tracy pour le profilage de l'exécution de Julia.
Mise à jour vers LLVM 15
Le suivi de LLVM en amont se poursuit et la version 1.10 de Julia utilise LLVM 15. Celle-ci apporte avec elle des profils mis à jour pour les nouveaux processeurs et des modernisations générales.
Le passage au nouveau gestionnaire de passes, qui promet des améliorations au niveau du temps de compilation, est particulièrement remarquable. LLVM 15 apporte un support amélioré pour Float16 sur x86.
Améliorations de la stabilité de Linux AArch64
Avec la mise à jour vers LLVM 15, il a été possible d'utiliser JITLink sur les processeurs aarch64 sous Linux. Ce linker, qui avait été introduit pour la première fois dans Julia v1.8 uniquement pour Apple Silicon (CPUs aarch64 sur macOS), résout les fréquentes erreurs de segmentation qui affectaient Julia sur cette plateforme. Cependant, en raison d'un bogue dans le gestionnaire de mémoire LLVM, les charges de travail non triviales peuvent générer trop de mappings de mémoire (mmap) qui peuvent dépasser la limite des mappings autorisés.
Génération parallèle de code natif pour les images système et les images de paquets
La compilation anticipée (AOT) a été accélérée en exposant le parallélisme pendant la phase de compilation de LLVM. Au lieu de compiler une grande unité de compilation monolithique, le travail est maintenant divisé en plusieurs petits morceaux. Ce multithreading accélère la compilation des images système ainsi que des grandes images de paquets, ce qui permet de réduire les temps de précompilation pour ces dernières.
La quantité de parallélisme utilisée peut être contrôlée par la variable d'environnement JULIA_IMAGE_THREADS=n. De plus, en raison des limitations des binaires COFF natifs de Windows, le multithreading est désactivé lors de la compilation d'images volumineuses sous Windows.
Prévention des courses lors de la précompilation parallèle
Dans les versions précédentes de Julia, plusieurs processus s'exécutant avec le même dépôt s'affrontent pour précompiler les paquets dans les fichiers de cache, ce qui entraîne un travail supplémentaire et une corruption potentielle de ces fichiers de cache.
La version 1.10 introduit un mécanisme de verrouillage "pidfile" (process id file) qui permet d'orchestrer les choses de telle sorte qu'un seul processus Julia travaille à la précompilation d'un fichier cache donné, où un fichier cache est spécifique à la configuration Julia qui est ciblée lors de la précompilation.
Cet arrangement profite à la fois aux utilisateurs locaux, qui peuvent exécuter plusieurs processus à la fois, et aux utilisateurs de calcul à haute performance qui peuvent exécuter des centaines de "workers" avec le même dépôt partagé.
Précompilation parallèle sur using
Alors que Pkg précompile automatiquement les dépendances en parallèle après l'installation, la précompilation qui se produit au moment d'using/import était auparavant sérielle, précompilant une dépendance à la fois.
Lors du développement d'un paquetage, les utilisateurs peuvent se retrouver à heurter la précompilation pendant le chargement, et si les changements de code dans les paquetages développés se trouvent profondément dans l'arbre de dépendance du paquetage chargé, le processus de précompilation en série peut s'avérer particulièrement lent.
La version 1.10 introduit la précompilation parallèle pendant le chargement afin d'éviter ces situations et d'accélérer la précompilation.
Source : Julia v1.10 Release Notes
Et vous ?
Que pensez-vous du langage de programmation Julia ?
Voir aussi :

 Répondre avec citation
Répondre avec citation
Partager