1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
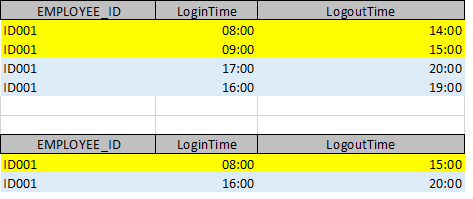
| with cte_data (Employee_Id, LoginTime, LogoutTime) as
(
select 8858043, timestamp '2024-01-06 07:58:48', timestamp '2024-01-06 14:03:05' union all
select 8858043, timestamp '2024-01-06 07:59:47', timestamp '2024-01-06 14:05:05' union all
select 8858043, timestamp '2024-01-06 15:00:06', timestamp '2024-01-06 18:05:40' union all
select 8858043, timestamp '2024-01-06 15:00:29', timestamp '2024-01-06 18:01:40'
)
, cte_LogoutMax (Employee_Id, LoginTime, LogoutTime, LogoutTime_max) as
(
select Employee_Id, LoginTime, LogoutTime
, max(LogoutTime) over(partition by Employee_Id order by LoginTime, LogoutTime rows unbounded preceding) as LogoutTime_max
from cte_data
)
, cte_GrpStart (Employee_Id, LoginTime, LogoutTime, GrpStart) as
(
select Employee_Id, LoginTime, LogoutTime
, case when LoginTime <= lag(LogoutTime_max) over(partition by Employee_Id order by LoginTime, LogoutTime) then 0 else 1 end
from cte_LogoutMax
)
, cte_GrpId (Employee_Id, LoginTime, LogoutTime, GrpId) as
(
select Employee_Id, LoginTime, LogoutTime
, sum(GrpStart) over(partition by Employee_Id order by LoginTime rows unbounded preceding)
from cte_GrpStart
)
select Employee_Id
, min(LoginTime) as LoginTime
, max(LogoutTime) as LogoutTime
from cte_GrpId
group by Employee_Id, GrpId
order by Employee_Id, GrpId;
Employee_Id LoginTime LogoutTime
----------- ------------------- -------------------
8858043 2024-01-06 07:58:48 2024-01-06 14:05:05
8858043 2024-01-06 15:00:06 2024-01-06 18:05:40 |







 Répondre avec citation
Répondre avec citation






















Partager