Ironwood : La première TPU de Google pour l'ère de l'inférence
Aujourd'hui, à l'occasion de Google Cloud Next 25, nous présentons Ironwood, la septième génération de notre Tensor Processing Unit (TPU), notre accélérateur d'IA personnalisé le plus performant et le plus évolutif à ce jour, et le premier conçu spécifiquement pour l'inférence. Depuis plus de dix ans, les TPU alimentent les charges de travail de Google les plus exigeantes en matière d'entraînement et de service d'IA, et permettent à nos clients Cloud d'en faire autant. Ironwood est notre TPU la plus puissante, la plus performante et la plus économe en énergie à ce jour. Il est conçu pour alimenter des modèles d'IA déductifs et réfléchis à grande échelle.
Ironwood représente un changement significatif dans le développement de l'IA et de l'infrastructure qui alimente ses progrès. Il s'agit de passer de modèles d'IA réactifs qui fournissent des informations en temps réel pour que les gens les interprètent, à des modèles qui fournissent une génération proactive d'idées et d'interprétations. C'est ce que nous appelons « l'ère de l'inférence », où les agents d'IA récupèrent et génèrent des données de manière proactive afin de fournir de manière collaborative des informations et des réponses, et pas seulement des données.
Ironwood est conçu pour prendre en charge cette nouvelle phase de l'IA générative et ses énormes exigences en matière de calcul et de communication. Il peut accueillir jusqu'à 9 216 puces refroidies par liquide et reliées par un réseau d'interconnexion inter-puces (ICI) d'une puissance de près de 10 MW. Il s'agit de l'un des nouveaux composants de l'architecture Google Cloud AI Hypercomputer, qui optimise le matériel et les logiciels pour les charges de travail d'IA les plus exigeantes. Avec Ironwood, les développeurs peuvent également tirer parti de la pile logicielle Pathways de Google pour exploiter facilement et en toute fiabilité la puissance de calcul combinée de dizaines de milliers de TPU Ironwood.
Voici un aperçu de la façon dont ces innovations fonctionnent ensemble pour répondre aux charges de travail de formation et de service les plus exigeantes avec des performances, des coûts et une efficacité énergétique inégalés.
L'ère de l'inférence avec Ironwood
Ironwood est conçu pour gérer avec élégance les exigences complexes en matière de calcul et de communication des « modèles de pensée », qui englobent les grands modèles de langage (LLM), les mélanges d'experts (MoE) et les tâches de raisonnement avancées. Ces modèles nécessitent un traitement parallèle massif et un accès efficace à la mémoire. En particulier, Ironwood est conçu pour minimiser les mouvements de données et la latence sur la puce tout en effectuant des manipulations massives de tenseurs. À la frontière, les exigences de calcul des modèles de réflexion dépassent largement la capacité d'une seule puce. Nous avons conçu les TPU Ironwood avec un réseau ICI à faible latence et à large bande passante pour prendre en charge une communication coordonnée et synchrone à l'échelle d'un pod TPU complet.
Pour les clients de Google Cloud, Ironwood est disponible en deux tailles en fonction des exigences de la charge de travail en matière d'IA : une configuration à 256 puces et une configuration à 9 216 puces.
- En passant à 9 216 puces par pod pour un total de 42,5 Exaflops, Ironwood prend en charge plus de 24 fois la puissance de calcul du plus grand supercalculateur du monde - El Capitan - qui n'offre que 1,7 Exaflops par pod. Ironwood offre la puissance de traitement parallèle massive nécessaire aux charges de travail d'IA les plus exigeantes, telles que les modèles LLM ou MoE denses de très grande taille avec des capacités de réflexion pour l'entraînement et l'inférence. Chaque puce individuelle offre une puissance de calcul maximale de 4 614 TFLOP. Cela représente un saut monumental dans les capacités de l'IA. L'architecture de mémoire et de réseau d'Ironwood garantit que les bonnes données sont toujours disponibles pour soutenir des performances maximales à cette échelle massive.
- Ironwood est également doté d'un SparseCore amélioré, un accélérateur spécialisé dans le traitement des embeddings ultra-larges, courants dans les charges de travail de classement et de recommandation avancés. La prise en charge élargie de SparseCore dans Ironwood permet d'accélérer un plus large éventail de charges de travail, notamment en dépassant le domaine traditionnel de l'IA pour s'étendre aux domaines financiers et scientifiques.
- Pathways, le propre runtime ML de Google développé par Google DeepMind, permet un calcul distribué efficace sur plusieurs puces TPU. Pathways sur Google Cloud permet d'aller au-delà d'un seul Ironwood Pod et de composer des centaines de milliers de puces Ironwood afin de repousser rapidement les limites du calcul de l'IA générique.

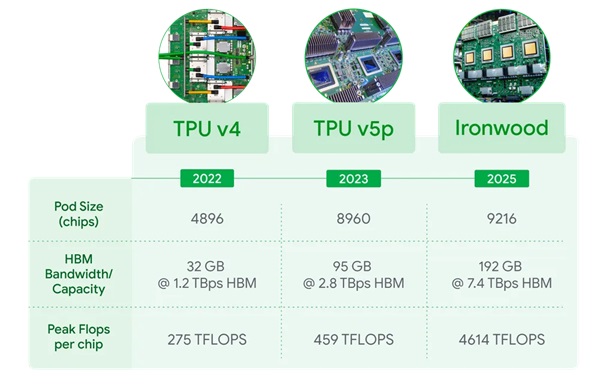
Principales caractéristiques d'Ironwood
Google Cloud est le seul hyperscaler avec plus d'une décennie d'expérience dans la fourniture de calcul d'IA pour soutenir la recherche de pointe, intégrée de manière transparente dans les services à l'échelle planétaire pour des milliards d'utilisateurs chaque jour avec Gmail, Search et plus encore. Toute cette expertise est au cur des capacités d'Ironwood. Les principales caractéristiques sont les suivantes :
- Des gains de performance significatifs tout en mettant l'accent sur l'efficacité énergétique, ce qui permet aux charges de travail d'IA de fonctionner de manière plus rentable. Les performances d'Ironwood sont multipliées par deux par rapport à Trillium, notre TPU de sixième génération annoncée l'année dernière. À une époque où l'énergie disponible est l'une des contraintes pour fournir des capacités d'IA, nous offrons une capacité par watt nettement supérieure pour les charges de travail des clients. Nos solutions avancées de refroidissement liquide et la conception optimisée de nos puces peuvent soutenir de manière fiable des performances jusqu'à deux fois supérieures à celles d'un refroidissement à l'air standard, même en cas de charges de travail AI lourdes et continues. En fait, Ironwood est près de 30 fois plus économe en énergie que notre première TPU Cloud de 2018.
- Augmentation substantielle de la capacité de la mémoire à large bande passante (HBM). Ironwood offre 192 Go par puce, soit 6 fois plus que Trillium, ce qui permet de traiter des modèles et des ensembles de données plus importants, en réduisant le besoin de transferts de données fréquents et en améliorant les performances.
- La bande passante HBM a été considérablement améliorée, atteignant 7,2 TBps par puce, soit 4,5 fois celle de Trillium. Cette bande passante élevée garantit un accès rapide aux données, ce qui est crucial pour les charges de travail à forte intensité de mémoire, courantes dans l'IA moderne.
- Amélioration de la bande passante de l'interconnexion inter-puces (ICI). Elle a été portée à 1,2 Tbps bidirectionnel, soit 1,5 fois celle de Trillium, ce qui permet une communication plus rapide entre les puces, facilitant ainsi l'apprentissage distribué et l'inférence à grande échelle.
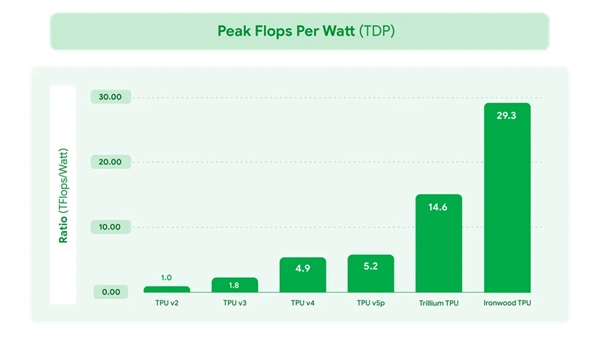
Ironwood représente une percée unique dans l'ère de l'inférence avec une puissance de calcul, une capacité de mémoire, des avancées en matière de réseau ICI et une fiabilité accrues. Ces avancées, associées à une efficacité énergétique presque deux fois supérieure, signifient que nos clients les plus exigeants peuvent prendre en charge des charges de travail de formation et de service avec les performances les plus élevées et la latence la plus faible, tout en répondant à l'augmentation exponentielle de la demande en matière de calcul. Des modèles de réflexion de pointe tels que Gemini 2.5 et AlphaFold, lauréat du prix Nobel, fonctionnent tous aujourd'hui sur des TPU. Avec Ironwood, nous sommes impatients de voir quelles percées en matière d'IA seront réalisées par nos propres développeurs et les clients de Google Cloud lorsqu'il sera disponible dans le courant de l'année.












Pensez-vous que cette annonce est crédible ou pertinente ?

 Répondre avec citation
Répondre avec citation
Partager