















Un "octave" c'est un ensemble d'étages consecutifs dans la pyramide (= les 'scale'). Chaque étage dans cet octave est calculé a partir de la même image de départ.Envoyé par NaguiM0

Quand on change d'octave, on calcule une nouvelle image de départ en reduisant par 2 les dimensions de l'image de l'octave précédant.
Dans cet exemple, on a 4 octaves (constitués chacun de 3 scales)

 Répondre avec citation
Répondre avec citation

 ? Je ne comprend pas bien la question.
? Je ne comprend pas bien la question. 
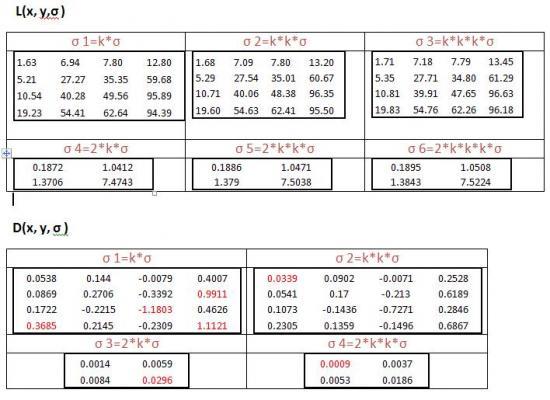
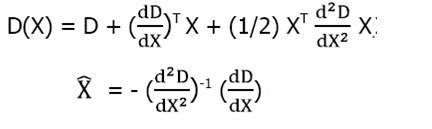
 . Mais je vais essayer d'expliquer le principe.
. Mais je vais essayer d'expliquer le principe. ,
,

Partager