











Bonjour.
je suis actuellement en train de tester un nouvel outil de Report, et je me suis attaqué à la partie "gestion des gros volumes de données".
Pour ce faire, j'utilise Oracle 10G Express edition.
J'ai, au préalable, créé 3 million de lignes sous excel, exportées dans Oracle via Access (qui mettait 20 minutes pour charger 1 malheureux million de lignes...)
Puis, j'ai démultiplié ces lignes sous Oracle, avec un code SQL tout simple:
DBMS_RANDOM sert à deux moments: pour générer le CA du client, et pour générer le numéro du commercial en charge du client.
Code : Sélectionner tout - Visualiser dans une fenêtre à part
2
3
4
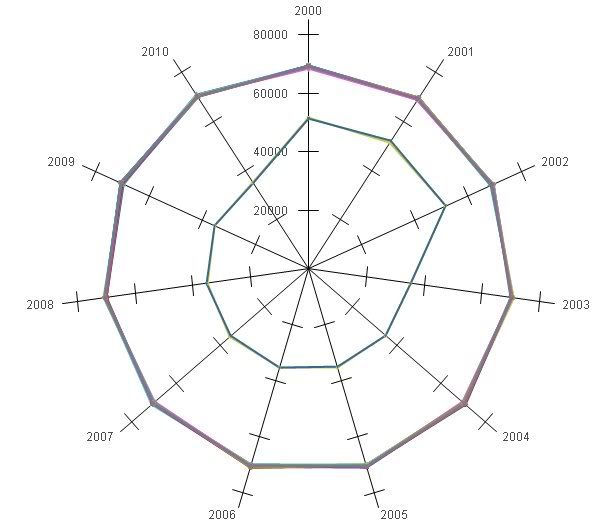
Bref, en partant de 3 millions de lignes, j'ai démultiplié le tout pour arriver à 22,4 millions de lignes.
J'ouvre mon merveilleux outil de report, et, oh stupeur, que vois-je apparaître:
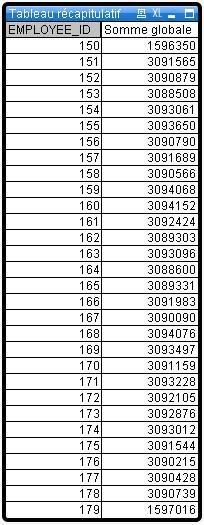
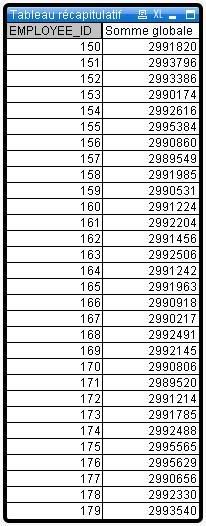
On observe que tous les commerciaux sont assez bien répartis, sauf 2 d'entre eux: les numéros 150 et 179, mes deux valeurs extrêmes.
Si on omet les 3 premières années (générées sous Excel, puis démultipliées sous Oracle pour gonfler les résultats), on remarque que les 2 valeurs extrèmes tombent exactement 50% de fois moins que les autres valeurs. Et chaque année correspond à environ 2 millions d'observations au total, donc le test est infaillible.
Est-ce normal? Sinon, comment y remédier?
 Répondre avec citation
Répondre avec citation







Partager