Bonjour Michka1111,
Merci de vous être intéressé à larticle.
Pas de quoi, plaisant à lire, tant sur la forme que sur le fond
Dans son exemple, Ullman limite lunivers du discours à lagenda de lannée en cours : il ne cherche pas à modéliser un historique.
mais la relation universelle est bel et bien adaptée pour supporter les requêtes étoiles (clauses where restrictives sur des colonnes), et peu adaptée aux modifications performantes, en raison des données inutiles à la transaction impliquées dans la modification (un enregistrement pour modifier une colonne).
Les données peuvent avoir à être modifiées, cas par exemple de la table CHR, quand il y aurait bilocation des professeurs (ou des étudiants), si un trigger tel que CHR_MAJ_TRIGGER ne linterdisait pas (situation à lépoque). Il est évident que si lon étendait les règles de gestion, par exemple quun professeur puisse être remplacé en cours dannée, on commencerait à rentrer dans le problème (pas trivial !) de la prise en compte de lhistorique, et là on pourrait aller très loin et séclater (cf.
la normalisation en 6NF).
Il faut voir si les règles de gestion sont utiles et effectives dans le fonctionnel modélisé, dans l'exemple, il y a déja des restrictions pleines de bon sens mais triviales partant du principe qu'une personne est dépourvue d'ubicité.
On nest pas ici dans un « système historique ». Je rappelle que lunivers du discours décrit par Ullman nest pas concerné par le temps.
Pourtant, sa Relation Universelle est bien issue de la modélisation en étoile
Le professeur nest pas plus concerné. Je vous renvoie à structure de la table CHR.
Oui, Un cours est prodigué par un professeur aux élèves inscrits à ce cours
Dans larticle, je traite de la modélisation conceptuelle des données. Ainsi, il y a un modèle conceptuel des données (MCD), dérivable en modèle logique des données (MLD) impliquant donc le MCD, dérivable à son tour en modèle physique des données (MPD), impliquant le MLD, donc le MCD (voyez lexcellent
Looping) du Professeur Bergougnoux. Dun point de vue théorique, laspect historique est parfaitement pris en compte par C. J. Date, Hugh Darwen et Nikos Lorentzos dans le cadre du modèle relationnel de données, mieux que je ne le ferais. Voyez leur ouvrage
Temporal Data and The Relational Model, ainsi que la synthèse de Hugh Darwen :
Temporal Data and The Relational Model.
Les séries temporelles sont différentes des schémas étoiles historiques des systèmes transactionnels, bien que basées elles aussi sur des historiques.
Oui, SQL Server a eu pas mal de difficulté avec la standardisation de "son" SQL, tout comme Analysis Services et Integration Services qui ont concervé leurs lacunes encore aujourd'hui.
Quils se mettent au diapason, à la modélisation conceptuelle avec Looping !
Un logiciel ne remplace pas un raisonnement intellectuel, mais je vais sans doute en avoir l'usage pour un (autre) projet et pour mes recherches sur les schémas étoiles (!).
Merci den fournir la démonstration.
Mon ouvrage de référence est Ralf Kimball "The Data Warehouse Toolkit" (assez bien traduit en français). La définition des entités fondamentales des schéma étoile se déduit de l'expression formelle d'un "fait" atomique empilé dans l'historique, expression formelle appelée le "grain" de l'historique, déduit d'une transaction tout aussi élémentaire survenant dans le système transactionnel, celui-ci n'étant pas conçu pour la mémoriser, mais pour présenter des données "à jour" à l'instant t d'un moment présent. Les entités fondamentales et les attribut du système transactionnel se retrouvent donc à un pour un dans le schéma étoile. La composante du temps absolu se rajoute en tant que concept dans l'expression formelle du grain, qui change seulement les cardinalités liées aux autres entités, ce qui fait "passer" le fait historique en une relation "universelle" vers les entités fondamentales des transactions. Après, l'application strictes des formes normales pour modéliser varie suivant l'utilisation principale de la base en écriture (transactions) ou en lecture (requêtes). Dans la pratique, la composante temps absolu fondamentale (en 3NF) dans le star schéma se retrouve complètement dénormalisée dans le système transactionnel (optimisé écriture) : dans les métadonnées d'audit et d'administration, et dans les logs des sgbd. Un star schéma ne crée (n'invente) absolument aucune donnée. Il y a d'ailleurs un débat (houleux) à propos de la qualité des données, de statuer si les données erronées doivent être modifiées dans l'entrepôt ou dans le système transactionnel, cette opération dans le système transactionnel coûtant très cher et prenant beaucoup de temps.
En outre, la prise en compte des données temporelles (historiques) impose de viser plus haut (6NF) !
Là encore, ça dépend de la vocation de la base en lecture ou en écriture, pour celle-ci, la Relation Universelle ne s'applique pas, concrètement parlant, vous l'avez, à mon avis, parfaitement montré dans l'article. De même, les entrepôts "logiques" ont leurs limites.
Bon courage,
François

















")
 Répondre avec citation
Répondre avec citation






 , merci François !
, merci François !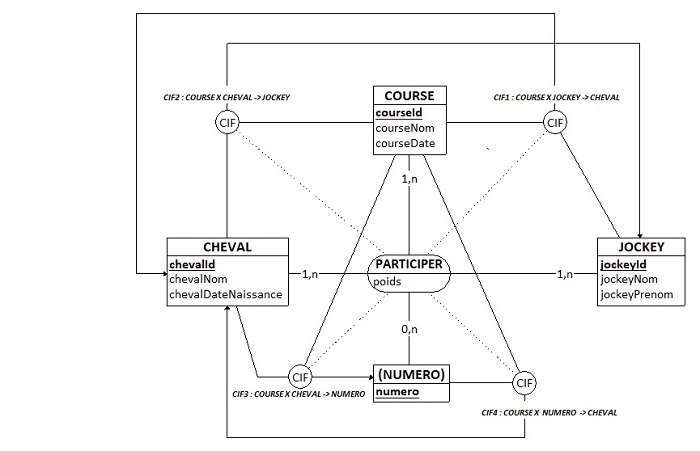



 !
!




.png)




 mais si ça vous arrive, surtout faites un grand flush sur le modèle et les bonnes pratiques existants, et repartez d'une feuille blanche, faites vous vos propres bonnes pratiques, ça vaudra mieux, mais pas sûr que votre client appréciera
mais si ça vous arrive, surtout faites un grand flush sur le modèle et les bonnes pratiques existants, et repartez d'une feuille blanche, faites vous vos propres bonnes pratiques, ça vaudra mieux, mais pas sûr que votre client appréciera 
 CHR (encapsulée dan la vue THR_V).
CHR (encapsulée dan la vue THR_V).

Partager